

En sistemas operativos, el bloqueo mutuo (también conocido como interbloqueo, traba mortal, deadlock, abrazo mortal) es el bloqueo permanente de un conjunto de procesos o hilos de ejecución en un sistema concurrente que compiten por recursos del sistema o bien se comunican entre ellos. A diferencia de otros problemas de concurrencia de procesos, no existe una solución general para los interbloqueos.
Todos los interbloqueos surgen de necesidades que no pueden ser satisfechas, por parte de dos o más procesos. En la vida real, un ejemplo puede ser el de dos niños que intentan jugar al arco y flecha, uno toma el arco, el otro la flecha. Ninguno puede jugar hasta que alguno libere lo que tomó.
Wait-for-graph
Cuando los tipos de recursos intervinientes tienen una única instancia se puede simplificar el grafo. Lo que se hace es obtener un grafo simplificado que se llaman wait-for-graph (WFG) que muestra cuales procesos están esperando por otros procesos. Este grafo se logra removiendo los nodos de recursos. Veamos el WFG del grafo siguiente:
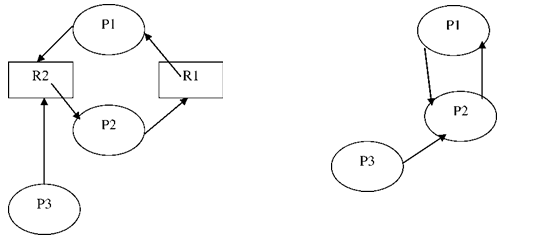
En WFG, dado que intervienen recursos con una sola instancia, un ciclo es condición necesaria y suficiente para deadlock.
Resaltamos algunos conceptos:
- Ciclo: es una path (cadena) donde el 1er y el ultimo nodo son los mismos
- Path: secuencia de nodos (a,b,c,…,i,j) de un grafo dirigido tal que (a,b), (b,c), (c,d)…(i,j) son arcos dirigidos. Un path debe tener como mínimo, 2 nodos.
- Grafo dirigido: es un par (N,E) donde N es un conjunto no vacío de nodos y E es un conjunto de arcos dirigidos.
- Arco dirigido: es un par ordenado (a,b) donde a y b son nodos de N.
Metodos para el tratamiento del deadlock
Hay 3 métodos:
- Usar un protocolo que asegure que NUNCA se entrara en estado de deadlock
- Permitir el estado de deadlock y luego recuperar
- Ignorar el problema y esperar que nunca haya un deadlock
Diferencia entre “prevention”y “avoidance”
Prevention (prevenir la formación del interbloqueo): se usan métodos que aseguran que por lo menos una de las condiciones no pueda mantenerse. Se imponen restricciones en la forma en que los procesos REQUIEREN los recursos.
Avoidance (evitar la formación del interbloqueo): asignar cuidadosamente los recursos, manteniendo información actualizada sobre requerimiento y el uso de recursos.
Importante: En la prevention, a diferencia que en el objetivo de evitar (avoidance) o detectar, no hay testeos de asignación en runtime.
Prevention: La exclusión mutua
- Considerar que hay recursos compartibles y no compartibles.
- Mantener la exclusión mutua para los compartibles
Prevention: Retención y espera
Se basa en que si un proceso requiere un recurso, debe liberar otros.
Alternativas:
- Un proceso debe requerir y reservar todos los recursos a usar antes de comenzar la ejecución (precedencia de los system calls que hacer requerimiento antes de cualquier otro system call)
- El proceso puede requerir recursos solo cuando no tiene ninguno.
Desventajas
- Baja utilización de recursos
- Posibilidad de inanición de alguno de los procesos (starvation, o espera infinita)
Prevention: No apropiación
Si un recurso no puede asignarse a un proceso y queda en wait, se liberan el resto de los recursos (apropiación). El proceso esperara ahora por todos sus recursos.
Se aplica normalmente a recursos tales como ciclos de CPU y espacio de memoria que pueden ser salvados y restablecidos luego.
Es importante para definir la preemption, si los recursos involucrados son “preemptables” o “no preemptables”.
Cuando los recursos son preemptables se puede optar por dos políticas:
- Si un proceso requiere un recurso que no esta disponible, todos los recursos que tiene asignado ese proceso son preempted (le son sacados) y se bloquea el proceso. Se desbloquea cuando el recurso pedido y los que tenia están nuevamente disponibles.
- Si un proceso requiere un recurso que no esta disponible, el sistema chequea si ese recurso lo tiene asignado un proceso que este bloqueado a la espera de otro recurso. Si es asi, el recurso es preempted del proceso bloqueado y asignado al solicitante. Si no es asi, el proceso solicitante es bloqueado hasta que el recurso este disponible. Algunos de los recursos que este proceso ya tenia asignado pueden ser preempted. Por lo tanto, en esta situación, se cumple lo dicho en la option 1 “se desbloquea cuando el recurso pedido y los que tenia están nuevamente disponibles”.
Estas alternativas son validas solo para recursos “preemptables”. Pero este modelo es atractivo en el ambiente distribuido.
Prevention: Espera circular
Se define un ordenamiento de los recursos. Luego, un proceso puede requerir recursos en un orden numerico ascendente:
Sea F:R^N, N conjunto de los naturales. F asigna un numero único a cada recurso (los números pequeños para recursos muy usados). Un proceso, que ya tiene R i puede requerir Rj si y solo si F(Rj) > F(Ri)
Ejemplo: Prevention en Espera circular
Supongamos que se han definido los siguientes valores:
F(zip)=1; F(disco duro)=4, F(impresora)=7
Un proceso que ya tiene asignado el disco, puede pedir la impresora (pues F(impresora)> F(disco duro). Si ya tiene la impresora, no puede solicitar el zip.
Como evitar el deadlock
Existen algoritmos que previenen el deadlock. Trabajan sobre el requerimiento de los recursos. Lo que hacen estos algoritmos es impedir que se cumplan las 4 condiciones. La consecuencia de su implementación es que habrá un mayor uso de la capacidad de procesamiento que puede producir una baja utilización de los recursos y de la performance del sistema.
Como evitar el deadlock: Algoritmos
- Algoritmo que determina el estado seguro de un sistema.
- Algoritmo del Banquero (para mas de una instancia por recurso)
Detección del deadlock. Recuperación
Si no contamos con prevention debemos contar con:
- Un algoritmo que examine si ocurrió un deadlock
- Un algoritmo para recuperación del deadlock
Recuperación desde el deadlock:
- El operador lo puede resolver manualmente.
- Esperar que el sistema se recupere automáticamente desde el deadock.
- Abortando todos o algunos procesos o hasta que el ciclo desaparezca sacándole recursos a procesos
Recuperación por apropiación de recursos
Considerar 3 puntos:
- Selección de procesos victima: a cuales les saco los recursos y que recursos?
- Rollback: debemos volver hacia una instancia segura al proceso que le sacamos los recursos? Lo aborto y reinicio? Es mas probable
- Starvation: asegurarnos de no sacarle los recursos siempre al mismo proceso
Ahora: que usar como criterio de selección, cuando se debe abortar o apropiar recursos de un proceso? Lo que se sugiere en la elección del proceso victima es optar por aquel con:
- Menor cantidad de tiempo de CPU consumido hasta el momento.
- Mayor tiempo restante estimado.
- Menor cantidad de recursos asignados hasta ahora.
- Prioridad mas baja.
