

Sin mucha presentación, continuamos.
Mailslots (Buzones)
Los buzones ofrecen a las aplicaciones una manera fácil de enviar y recibir mensajes cortos, y los mismos están integrados con la API de Windows. Si bien buzones proveen una comunicación de un solo sentido, un proceso puede al mismo tiempo ser servidor de buzón y un cliente de un buzón; de esta manera, una comunicación de doble sentido puede ser posible usando múltiples buzones. Los mensajes de entrada son siempre adjuntados al buzón. Los buzones guardan los mensajes hasta que el servidor del buzón los haya leídos.
Un servidor de buzón crea un buzón a través de la función CreateMailslot, la cual acepta un nombre del formulario “\\.\Mailslot\MailslotName” como parámetro de entrada. Cabe aclarar que un servidor de buzón sólo puede crear buzones en la computadora en la que se está ejecutando, y el nombre que es asignado al buzón puede incluir subdirectorios. CreateMailslot también toma un descriptor de seguridad que controla los accesos de clientes al buzón. Los manejadores (handles) devueltos por la función CreateMailslot están “superpuestos” (overlapped), lo que significa que las operaciones realizadas sobre los manejadores, tales como enviar y recibir mensajes, son sincrónicas.
Debido a que los buzones son unidireccionales y poco seguros, CreateMailslot no toma muchos parámetros como sí lo hace CreateNamedPipe. Después de crear un buzón, un servidor simplemente “escucha” los mensajes entrantes de los clientes ejecutando la función ReadFile sobre el manejador que representa al buzón.
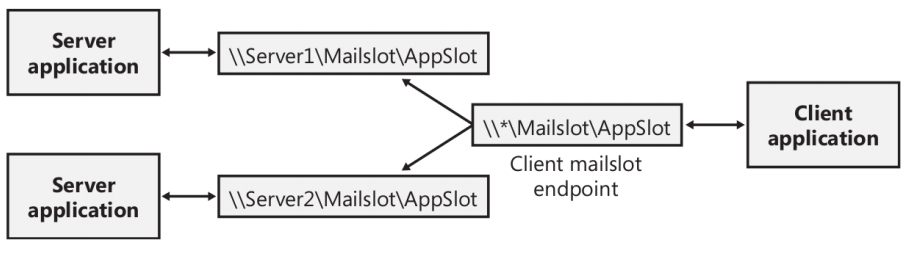
Los clientes de buzón usan un formato de nombramiento similar al usado por los clientes de tuberías, pero con variantes que hacen posible enviar mensajes de broadcast a todos los buzones con un nombre dado dentro del dominio del cliente o de un dominio específico. Para enviar un mensaje a una instancia particular de un buzón, el cliente invoca CreateFile, especificando el nombre específico de la computadora. Un ejemplo de un nombre sería “\\Server\Mailslot\MailslotName” (El cliente puede especificar “\\.\” para representar la computadora local). Si el cliente quiere obtener el manejador que representa todos los buzones de un nombre dado en el dominio del cual es miembro, especifica el nombre con el formato “\\*\Mailslot\MailslotName”, y si el cliente quiere enviar un mensaje de broadcast a todos los buzones de un nombre dado dentro de un dominio diferente, el formato usado es “\\DomainName\Mailslot\MailslotName”.
Luego de obtener el manejador que representa el lado del cliente de un buzón, el cliente envía mensajes a través de la invocación de WriteFile. Debido a la forma en que están implementados los buzones, sólo los mensajes menores a 425 bytes pueden ser enviados por broadcast. Si un mensaje supera dicho tamaño, la implementación del buzón usa un mecanismo de comunicación poco fiable que requiere una conexión de uno-a-uno entre cliente y servidor, que imposibilita la capacidad de transmitir en broadcast. También, un capricho de la implementación de los buzones causa que cualquier mensaje de 425 o 426 bytes sea truncado a 424 bytes. Estas limitaciones hacen a los buzones generalmente inadecuados para los mensajes mayores a 424 bytes. Por otro lado, los mensajes enviados a un solo buzón son limitados sólo por el tamaño máximo de mensajes especificado por el servidor de buzón cuando dicho buzón es creado.
La siguiente figura muestra un ejemplo de un cliente enviando un mensaje de broadcast a múltiples servidores de buzones dentro de un dominio:
RPC (Remote Procedure Call) y LPC (Local Procedure Call)
Remote Procedure Call
La habilidad de RPC es aquella que permite a un programador crear una aplicación que consiste en algún número de procedimientos, algunos que se ejecutan localmente y otros que se ejecutan en una computadora remota a través de una red de trabajo. Provee una vista procedural de las operaciones en red en lugar de una vista centrada en el transporte, simplificando así el desarrollo de aplicaciones distribuidas. De esta manera, RPC hace que IPC sea tan fácil como invocar una función.
El RPC provisto por Windows cumple con el Entorno de Computación Distribuida (DCE, Distributed Computing Environment) de la Fundación de Software Abierto (OSF, Open Software Foundation). Esto significa que las aplicaciones que usan RPC son capaces de comunicarse con aplicaciones que corren en otros sistemas operativos que soporten DCE. RPC automáticamente soporta conversión de datos teniendo en cuenta las diferentes arquitecturas de hardware y para el ordenamiento de bytes entre distintos entornos.
Los clientes y servidores RPC están estrechamente acoplados pero aún mantienen un alto rendimiento. El sistema hace uso extensivo de RPC para facilitar las relaciones cliente/servidor entre diferentes partes del sistema operativo.
El software para trabajo en red es tradicionalmente estructurado en torno a un modelo de E/S de procesamiento. En Windows, por ejemplo, una operación en red es iniciada cuando una aplicación emite un requerimiento de E/S remoto. El sistema operativo procesa en consecuencia, mediante la transmisión de un redirector, que actúa como un sistema de archivos remoto al hacer la interacción del cliente con el sistema de archivos remoto invisible para el cliente. El redirector pasa la operación al sistema de archivos remoto, y luego que el sistema remoto completa la solicitud y devuelve el resultado, la tarjeta de red local interrumpe. El kernel maneja la interrupción, y la operación de E/S original se completa, devolviendo los resultados a quién invocó.
RPC tiene un enfoque totalmente diferente. Las aplicaciones RPC son como otras aplicacionesestructuradas, con un programa principal que invoca procedimientos o librerías de procedimientos para realizar tareas específicas. La diferencia entre aplicaciones RPC y aplicaciones regulares, sin embargo, es que algunas de las librerías de procedimientos en una aplicación RPC se ejecutan en computadoras remotas, como se muestra en la siguiente figura, mientras otros se ejecutan localmente.
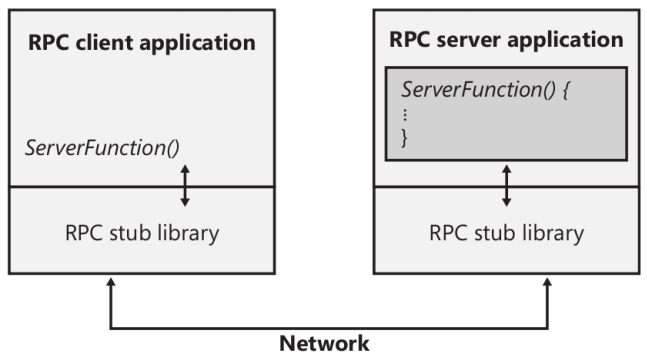
Para la aplicación RPC, todos los procedimientos aparentan ejecutarse localmente. En otras palabras, en lugar de que un programador activamente escriba código para transmitir peticiones de cálculo o de relacionadas con E/S través de una red, manejar protocolos de red, tratar con error de red, esperar por resultados, y así sucesivamente, el software RPC maneja estas cuestiones automáticamente. Y la habilidad de RPC de Windows puede operar sobre cualquier transporte disponible que esté cargado en el sistema.
Para escribir una aplicación RPC, el programador decide que procesos se ejecutarán localmente y cuales lo hará remotamente.
Las aplicaciones RPC funcionan de la siguiente manera: mientras una aplicación se está ejecutando, invoca tanto a procedimientos locales como a aquellos que no están presentes en la máquina local. Para manejar este último caso, la aplicación se enlaza con una librería de enlace estático o una DLL que contiene los procedimientos “stubs”, uno por cada procedimiento remoto. Para aplicaciones simples, los procedimientos stubs están enlazados estáticamente con la aplicación, pero para componentes más grandes los stubs se incluyen en archivos DLL independientes. Los procedimientos stubs tienen el mismo nombre y usan la misma interfaz que los procedimientos remotos, pero en lugar de realizar las operaciones requeridas el stub toma los parámetros que recibe y los ordena para transmitirlos a lo largo de la red. Ordenarlos significa organizarlos y empaquetarlos de una manera particular para adaptarse al en lace de red, tales como resolver las referencias y recoger una copia de cualquier estructuras de datos a las que un puntero se refiere.
El stub entonces invoca los procedimientos RPC de tiempo de ejecución que se encuentran en la computadora donde residen los procedimientos remotos, determina que mecanismos de transporte que esa computadora usa y envía la petición de utilizar software de transporte local. Cuando el servidor remoto recibe la petición RPC, “desordena” los parámetros (de manera inversa a la cual fueron ordenados), reconstruye la invocación al procedimiento original, e invoca dicho procedimiento. Cuando el servidor termina realiza la secuencia inversa para devolver los resultados a quien realizó la invocación.
Además de la interfaz sincrónica basada en llamadas a funciones recién descripta, el RPC de Windows también soporta RPC asincrónico, el cual permite a una aplicación RPC ejecutar una función pero no espera hasta que la función sea completada para continuar con el procesamiento. En su lugar, la aplicación puede ejecutar otro código y después, cuando recibe una respuesta del servidor, la ejecución del RPC notifica al cliente que la operación ha sido completada. La ejecución del RPC utiliza el mecanismo de notificación solicitado por el cliente. Si el cliente utiliza un objeto de sincronización de eventos para notificar, espera por la señalización del objeto de evento llamando a la función WaitForSingleObject o WaitForMultipleObject. Si el cliente proporciona una llamada a procedimiento asincrónico (APC), se encola la ejecución del APC al hilo que ejecuto la función de RPC. Si el cliente utiliza un puerto de E/S de terminación como su mecanismo de notificación, debe invocar GetQueuedCompletionStatus para saber acerca de la terminación de la función. Alternativamente, un cliente puede consultar por la terminación de la función invocando RcpAsyncGetCallStatus.
Además de la ejecución RPC, la habilidad de RPC de Windows incluye un compilador, llamado compilador Microsoft Interface Definition Language (MIDL). Dicho compilador simplifica la creación de una aplicación RPC. El programador escribe una serie de prototipos de funciones ordinarias (asumiendo una aplicación C o C++) que describe las rutinas remotas y donde se alocan dichas rutinas en un archivo. El programador agrega entonces información adicional a estos prototipos, tal como un identificador de red único para el paquete de rutinas y un número de versión, además de los atributos que especifican si los parámetros son de entrada, salida o ambos. Los prototipos adornados forman el archivo de Lenguaje de Definición de Interfaz (IDL) de desarrollador.
Una vez que el archivo IDL es creado, el programador lo compila con el compilador MIDL que produce tanto rutinas stubs del lado del cliente como del lado del servidor, como también archivos de cabecera que son incluidos en la aplicación. Cuando el lado del cliente de una aplicación es enlazada al archivo de rutinas stubs, todas las referencias a procedimientos remotos son resueltas. Los procedimientos remotos son entonces instalados, usando un proceso similar, en el servidor. Un programador que quiere invocar una aplicación RPC existente sólo necesita escribir el software del lado del cliente y enlazar la aplicación a la habilidad de ejecución de RPC local.
El tiempo de ejecución de RPC utiliza un interfaz proveedor de transporte genérico de RPC para hablar con un protocolo de transporte. Dicha interfaz actúa como una fina capa entre la habilidad de RPC y el transporte, mapeando las operaciones RPC en las funciones provistas por el transporte.
La mayoría de los servicios de red de Windows son aplicaciones RPC, lo que significa que tanto los procesos locales como los procesos en computadoras remotas pueden invocarlos. Así, un equipo cliente remoto puede llamar al servicio de servidor para la lista de acciones, abrir archivos, escribir en colas de impresión, o activar los usuarios en su servidor, o puede llamar el servicio de mensajería para mensajes directos a uno (todo sujeto a restricciones de seguridad, por supuesto). Server name publishing, que es la habilidad de un servidor para registrar su nombre en un lugar accesible para la búsqueda de clientes, está en RPC y se integra con Active Directory. Si Active Directory no está instalado, los servicios de localización de nombres RPC recurren a la difusión de NetBIOS. Este comportamiento garantiza la interoperabilidad con Windows NT 4 sistemas RPC y permite que funcione en servidores y estaciones de trabajo independientes.
Local Procedure Call
Por otro lado, una llamada a un procedimiento local (LPC) facilita el pasaje de mensajes entre procesos cliente y procesos servidores en una misma computadora. LPC es una versión flexible y optimizada de RPC.
LPC es una habilidad de comunicación entre procesos para el pasaje de mensajes a alta velocidad. No está directamente disponible a través de la API de Windows; es un mecanismo interno disponible solo para los componentes del sistema operativo Windows.
A continuación algunos ejemplos de dónde se utilizan LPCs:
- Las aplicaciones de Windows que utilizan RPCs, indirectamente usan LPCs cuando se especifica un RPC local (una forma de RPC para comunicar procesos en un mismo sistema).
- Algunas APIs de Windows que terminan en enviar mensajes a los procesos de los subsistemas de Windows.
- Winlogon utiliza LPCs para comunicarse con el proceso servidor de autenticación de seguridad local, LSASS.
- El monitor de referencia de seguridad también utiliza LPCs para comunicarse con el proceso LSASS.
Típicamente, las LPC son utilizadas entre procesos servidores y uno o más procesos clientes de ese servidor. Una conexión por LPC puede ser establecida entre dos procesos de modo usuario o entre un componente del modo kérnel y un proceso en modo usuario.
Las LPCs están diseñadas de manera tal que permite tres métodos para intercambiar mensajes:
- Un mensaje que es más corto que 256 bytes puede ser enviado invocando una LPC con un buffer que contenga el mensaje. Este mensaje es así copiado del espacio de direcciones del proceso remitente al espacio de direcciones del sistema, y de ahí al espacio de direcciones del proceso receptor.
- Si un cliente y un servidor quiere intercambiar más que 256 bytes de información, ellos pueden elegir usar una sección compartida en la cual ambos estén mapeados. El remitente coloca la información del mensaje en una sección compartida, y luego le envía al receptor un pequeño mensaje con los punteros a la sección compartida donde se encuentra la información.
- Cuando un servidor quiere leer o escribir cantidades más grandes de información a la que cabe en una sección compartida, puede directamente leer desde o escribir en el espacio de direcciones del cliente. El componente de LPC suministra dos funciones que un servidor puede usar para lograr esto. Un mensaje enviado por la primera función es usado para sincronizar el pasaje del mensaje.
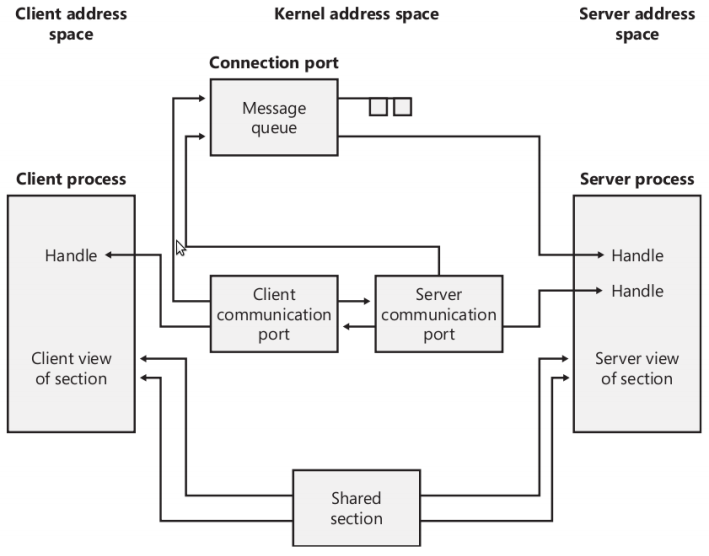
Una LPC exporta un único objeto ejecutivo llamado port object para mantener el estado necesitado para la comunicación. Aunque una LPC usa un sólo tipo de objeto, tiene varios tipos de puertos:
- Server connection port: puerto de conexión de servidor, es un puerto nombrado que es un punto de solicitud de conexión del servidor. Los clientes pueden conectarse al servidor a través de este puerto.
- Server communication port: puerto de comunicación de servidor, es un puerto sin nombrar que un servidor utiliza para comunicarse con un cliente en particular. El servidor tiene uno de estos puertos por cliente activo.
- Client communication port: puerto de comunicación de cliente, es un puerto sin nombrar que un hilo cliente en particular utiliza para comunicarse con un servidor en particular.
- Unnamed communication port: puerto de comunicación sin nombrar, es un puerto sin nombrar creado para ser usado por dos hilos en un mismo proceso.
Las LPCs son usadas típicamente de la siguiente manera: un servidor crea un objeto de un puerto de conexión de servidor nombrado. Un cliente hace una petición para conectarse a ese puerto. Si la petición es concedida, dos nuevos puertos sin nombrar son creados, un puerto de comunicación del cliente y un puerto de comunicación del servidor. El cliente obtiene un manejador para el puerto de comunicación del cliente, y el servidor obtiene un manejador para el puerto de comunicación del servidor. El cliente y el servidor usarán entonces estos nuevos puertos para su comunicación.
A continuación una imagen con una comunicación completa entre un cliente y un servidor:
Sockets de Windows (WinSock)
Los sockets de Windows son una interface de protocolo independiente. Se aprovechan de las capacidades de comunicación de los protocolos subyacentes. En Windows sockets 2, el manejador de un socket puede opcionalmente ser usado como el manejador de un archivo con funciones estándar de E/S de archivos.
Los sockets de Windows originales (versión 1.0) estaban basados en los sockets que fueron popularizados en un principio por BSD (Berkeley Software Distribution). Una aplicación que utilice los sockets de Windows puede comunicarse con otras implementaciones de sockets en otros tipos de sistemas. Sin embargo, no todos los proveedores de servicios de transporte son compatibles con todas las opciones disponibles.
Los sockets de Windows (de ahora en más, denominados WinSock) modernos incluyen casi todas las funcionalidades que los sockets BSD, pero también incluyen mejoras específicas de Windows, las cuales continúan evolucionando. WinSock soporta tanto comunicaciones orientadas a la conexión segura, como comunicaciones orientadas a conexión poco fiables. Windows provee WinSock 2.2, el cual está incluido o está disponible como un add-on para todas las versiones actuales de Windows. WinSock 2.2 agrega numerosas característica más allá de la especificación de los sockets BSD, tales como agregar funciones que aprovechan la E/S asincrónica de Windows, lo cual ofrece mucho mayor rendimiento y escalabilidad que la programación lineal de sockets BSD.
WinSock incluye las siguientes características:
- Soporte de dispersión-recopilación y E/S de aplicaciones asincrónicas.
- Convenciones de Calidad de Servicio (QoS) para que las aplicaciones puedan negociar requerimientos de latencia y ancho de banda cuando la red subyacente soporta QoS.
- Extensibilidad para que WinSock pueda ser usado con otros protocolos más allá de los que requiere Windows para que sea soportado.
- Soporte para otros espacios de nombre integrados más allá de aquellos definidos por un protocolo que una aplicación está usando con WinSock.
- Soporte para mensajes multipuntos, donde los mensajes se transmitan desde una sola fuente hacia múltiples receptores, simultáneamente.
Operación de un cliente WinSock
El primer paso que una aplicación WinSock realiza es para inicializar la API WinSock con una invocación a una función de inicialización.
En un sistema Windows 2000, el próximo paso de una aplicación WinSock es crear el socket que representará el punto final de la comunicación. La aplicación obtiene la dirección de un servidor al que quiere conectarse invocando gethostbyname. WinSock es una API de protocolo independiente, por lo que una dirección puede ser especificada para cualquier protocolo instalado en el sistema sobre los cuales WinSock opera (TCP/IP, TCP/IPv6, IPX). Luego de obtener el nombre del servidor, un cliente orientado a conexión intenta conectar con el servidor usando connect y especificando la dirección del servidor.
En Windows XP y Windows Server 2003, una aplicación debería utilizar getaddrinfo para obtener la dirección de un servidor en lugar de utilizar gethostbyname. Getaddrinfo devuelve la lista de direcciones asignadas al servidor, y el cliente intenta conectar a cada uno hasta que es posible establecer una conexión con uno de ellos. Esto asegura que un cliente que solo soporta IPv4, por ejemplo, se conecte con la dirección IPv4 apropiada de un servidor que podría tener asignadas tanto direcciones IPv4 como IPv6. Cuando una conexión es establecida, el cliente puede enviar y recibir información sobre su socket usando recv y send, por ejemplo. Un cliente sin conexión especifica la dirección remota con APIs sin conexión, tales como los equivalentes sin conexión de send y recv, sendto y recvfrom.
Operación de un servidor WinSock
La secuencia de pasos para una aplicación servidor difiere de aquella de un cliente. Luego de inicializar la API WinSock, el servidor crea un socket y luego lo enlaza a una dirección local usando bind. De nuevo, la especificación del tipo dirección depende de la aplicación servidora. Si el servidor es orientado a conexión, se realiza una operación listen sobre el socket, indicando el número de conexiones que el socket puede soportar. Luego, se realiza una operación accept para permitir a un cliente conectarse al socket. Si hay un pedido de conexión pendiente, la invocación de accept lo completa inmediatamente; de otro modo, se completa cuando una petición de conexión llega. Cuando una conexión es hecha, la función accept devuelve un nuevo socket que representa el final de la conexión del servidor. El servidor, además, puede realizar operaciones de recibir y enviar usando las operaciones recv y send, respectivamente.
La siguiente figura muestra una comunicación orientada a conexión entre un cliente y un servidor WinSock:
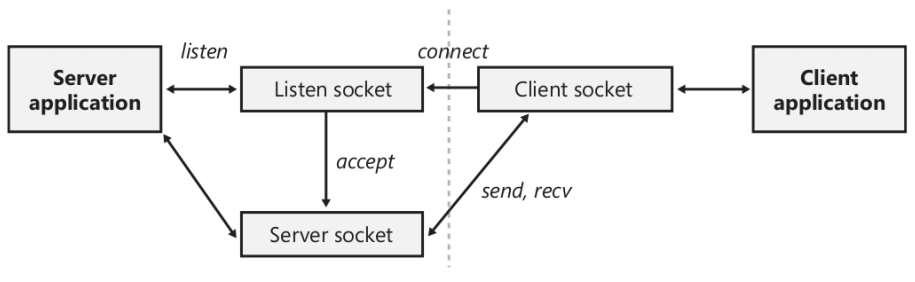
Luego de enlazar una dirección, un servidor sin conexión no es diferente de un cliente sin conexión: puede enviar y recibir información por el socket simplemente especificando la dirección remota con cada operación. La mayoría de los protocolos sin conexión son poco fiables y en general no sabrán si el receptor recibió la información enviada.
Espero les sirva ?
