

A través de los años, los científicos de la computación han identificado diversas técnicas generales que a menudo producen algoritmos eficientes para la resolución de muchas clases de problemas. Este capítulo presenta algunas de las técnicas más importantes como son: recursión, dividir para conquistar, técnicas ávidas, el método de retroceso y programación dinámica.
Se debe, sin embargo, destacar que hay algunos problemas, como los NP completos, para los cuales ni éstas ni otras técnicas conocidas producirán soluciones eficientes. Cuando se encuentra algún problema de este tipo, suele ser útil determinar si las entradas al problema tienen características especiales que se puedan explotar en la búsqueda de una solución, o si puede usarse alguna solución aproximada sencilla, en vez de la solución exacta, difícil de calcular.
| Recursión |
La recursividad es una técnica fundamental en el diseño de algoritmos eficientes, que está basada en la solución de versiones más pequeñas del problema, para obtener la solución general del mismo. Una instancia del problema se soluciona según la solución de una o más instancias diferentes y más pequeñas que ella.
Es una herramienta poderosa que sirve para resolver cierto tipo de problemas reduciendo la complejidad y ocultando los detalles del problema. Esta herramienta consiste en que una función o procedimiento se llama a sí mismo.
Una gran cantidad de algoritmos pueden ser descritos con mayor claridad en términos de recursividad, típicamente el resultado será que sus programas serán más pequeños.
La recursividad es una alternativa a la iteración o repetición, y aunque en tiempo de computadora y en ocupación en memoria es la solución recursiva menos eficiente que la solución iterativa, existen numerosas situaciones en las que la recursividad es una solución simple y natural a un problema que en caso contrario ser difícil de resolver. Por esta razón se puede decir que la recursividad es una herramienta potente y útil en la resolución de problemas que tengan naturaleza recursiva y, por ende, en la programación.
Existen numerosas definiciones de recursividad, algunas de las más importantes o sencillas son éstas:
- Un objeto es recursivo si figura en su propia definición.
- Una definición recursiva es aquella en la que el objeto que se define forma parte de la definición (recuerde la regla gramatical: lo definido nunca debe formar parte de la definición)
La característica importante de la recursividad es que siempre existe un medio de salir de la definición, mediante la cual se termina el proceso recursivo.
Ventajas:
- Puede resolver problemas complejos.
- Solución más natural.
Desventajas:
- Se puede llegar a un ciclo infinito.
- Versión no recursiva más difícil de desarrollar.
- Para la gente sin experiencia es difícil de programar.
| Tipos de Recursividad |
· Directa o simple: un subprograma se llama a si mismo una o más veces directamente.
· Indirecta o mutua: un subprograma A llama a otro subprograma B y éste a su vez llama al subprograma A.
- Propiedades para un Procedimiento Recursivo
- Debe de existir cierto criterio (criterio base) en donde el procedimiento no se llama a sí mismo. Debe existir al menos una
solución no recursiva. - En cada llamada se debe de acercar al criterio base (reducir rango). El problema debe reducirse en tamaño, expresando el nuevo problema en términos del propio problema, pero más pequeño.
- Los algoritmos de divide y vencerás pueden ser procedimientos recursivos.
- Debe de existir cierto criterio (criterio base) en donde el procedimiento no se llama a sí mismo. Debe existir al menos una
- Propiedades para una Función Recursiva
- Debe de haber ciertos argumentos, llamados valores base para los que la función no se refiera a sí misma.
- Cada vez que la función se refiera así misma el argumento de la función debe de acercarse más al valor base.
Ejemplos:
Factorial
n! = 1 * 2 * 3 … * (n-2) * (n-1) * n
0! = 1
1! = 1
2! = 1 * 2
3! = 1 * 2 * 3
…
n! = 1 * 2 * 3 … * (n-2) * (n-1) * n
⇒ n! = n* (n-1)!
si n = 0 entonces n! = 1
si n > 0 entonces n! = n * (n-1)!
Function factorial(n:integer):longint:
begin
if ( n = 0 ) then
factorial:=1
else
factorial:= n * factorial( n-1);
end;
Rastreo de ejecución:
Si n = 6 — Nivel
1) Factorial(6)= 6 * factorial(5) = 720
2) Factorial(5)=5 * factorial(4) = 120
3) Factorial(4)=4 * factorial(3) = 24
4) Factorial(3)=3 * factorial(2) = 6
5) Factorial(2)=2 * factorial(1) = 2
6) Factorial(1)=1 * factorial(0) = 1
7) Factorial(0)=1
La profundidad de un procedimiento recursivo es el número de veces que se llama a sí mismo.
Serie de Fibonacci
0, 1, 1, 2, 3, 5, 8, …
F0 = 0
F1 = 1
F2 = F1 + F0 = 1
F3 = F2 + F1 = 2
F4 = F3 + F2 = 3
…
Fn = Fn-1 + Fn-2
si n= 0, 1 Fn = n
si n >1 Fn = Fn-1 + Fn-2
Procedure fibo(var fib:longint; n:integer);
var
fibA, fibB : integer;
begin
if ( n = 0) or ( n = 1) then fib:=n
else begin
fibo(fibA,n-1);
fibo(fibB,n-2);
fib:=fibA + FibB;
end;
end;
function fibo ( n:integer) : integer;
begin
if ( n = 0) or ( n = 1) then
fibo:=n
else
fibo:=fibo(n-1) + fibo(n-2);
end;
end;
No todos los ambientes de programación proveen las facilidades necesarias para la recursión y adicionalmente, a veces su uso es una fuente de ineficiencia inaceptable. Por lo cual se prefiere eliminar la recursión. Para ello, se sustituye la llamada recursiva por un lazo, donde se incluyen algunas asignaciones para recolocar los parámetros dirigidos a la función.
Remover la recursión es complicado cuando existe más de una llamada recursiva, pero una vez hecha ésta, la versión del algoritmo es siempre más eficiente.
| Dividir para Conquistar |
Muchos algoritmos útiles tienen una estructura recursiva, de modo que para resolver un problema se llaman recursivamente a sí mismos una o más veces para solucionar subproblemas muy similares.
Esta estructura obedece a una estrategia dividir-y-conquistar, en que se ejecuta tres pasos en cada nivel de la recursión:
- Dividir. Dividen el problema en varios subproblemas similares al problema original pero de menor tamaño;
- Conquistar. Resuelven recursivamente los subproblemas si los tamaños de los subproblemas son suficientemente pequeños, entonces resuelven los subproblemas de manera directa; y luego,
- Combinar. Combinan estas soluciones para crear una solución al problema original.
La técnica Dividir para Conquistar (o Divide y Vencerás) consiste en descomponer el caso que hay que resolver en subcasos más pequeños, resolver independientemente los subcasos y por último combinar las soluciones de los subcasos para obtener la solución del caso original.
Caso General
Consideremos un problema arbitrario, y sea A un algoritmo sencillo capaz de resolver el problema. A debe ser eficiente para casos pequeños y lo denominamos subalgoritmo básico.
El caso general de los algoritmos de Divide y Vencerás (DV) es como sigue:
función DV(x)
{
si x es suficientemente pequeño o sencillo entonces
devolver A(x)
descomponer x en casos más pequeños x1, x2, x3 , … , xl
para i ¬ 1 hasta l hacer
yi ¬ DV(xi)
recombinar los yi para obtener una solución y de x
devolver y
}
El número de subejemplares l suele ser pequeño e independiente del caso particular que haya que resolverse. Para aplicar la estrategia Divide y Vencerás es necesario que se cumplan tres condiciones:
- La decisión de utilizar el subalgoritmo básico en lugar de hacer llamadas recursivas debe tomarse cuidadosamente.
- Tiene que ser posible descomponer el caso en subcasos y recomponer las soluciones parciales de forma eficiente.
- Los subcasos deben ser en lo posible aproximadamente del mismo tamaño.
En la mayoría de los algoritmos de Divide y Vencerás el tamaño de los l subcasos es aproximadamente m/b, para alguna constante b, en donde m es el tamaño del caso (o subcaso) original (cada subproblema es aproximadamente del tamaño 1/b del problema original).
El análisis de tiempos de ejecución para estos algoritmos es el siguiente:
Sea g(n) el tiempo requerido por DV en casos de tamaño n, sin contar el tiempo necesario para llamadas recursivas. El tiempo total t(n) requerido por este algoritmo de Divide y Vencerás es parecido a:
t(n) = l t(n/ b) + g(n) para l = 1 y b = 2
siempre que n sea suficientemente grande. Si existe un entero k = 0 tal que:
g(n) ∈ Θ(nk),
se puede concluir que:
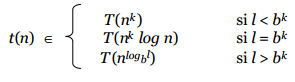
Se deja propuesta la demostración de esta ecuación de recurrencia usando análisis asintótico.
| Programación Dinámica |
Frecuentemente para resolver un problema complejo se tiende a dividir este en subproblemas más pequeños, resolver estos últimos (recurriendo posiblemente a nuevas subdivisiones) y combinar las soluciones obtenidas para calcular la solución del problema inicial.
Puede ocurrir que la división natural del problema conduzca a un grannúmero de subejemplares idénticos. Si se resuelve cada uno de ellos sin tener en cuenta las posibles repeticiones, resulta un algoritmo ineficiente; en cambio si se resuelve cada ejemplar distinto una sola vez y se conserva el resultado, el algoritmo obtenido es mucho mejor.
Esta es la idea de la programación dinámica: no calcular dos veces lo mismo y utilizar normalmente una tabla de resultados que se va rellenando a medida que se resuelven los subejemplares.
La programación dinámica es un método ascendente. Se resuelven primero los subejemplares más pequeños y por tanto más simples. Combinando las soluciones se obtienen las soluciones de ejemplares sucesivamente más grandes hasta llegar al ejemplar original.
Ejemplo:
Consideremos el cálculo de números combinatorios. El algoritmo sería:
función C(n, k)
si k=0 o k=n entonces devolver 1
si no devolver C(n-1, k-1) + C(n-1, k)
Ocurre que muchos valores C(i, j), con i < n y j < k se calculan y recalculan varias veces. Un fenómeno similar ocurre con el algoritmo de Fibonacci. La programación dinámica se emplea a menudo para resolver problemas de optimización que satisfacen el principio de optimalidad: en una secuencia óptima de decisiones toda subsecuencia ha de ser también óptima.
Ejemplo:
Si el camino más corto de Santiago a Copiapó pasa por La Serena, la parte del camino de Santiago a La Serena ha de ser necesariamente el camino mínimo entre estas dos ciudades. Podemos aplicar esta técnica en:
- Camino mínimo en un grafo orientado
- Árboles de búsqueda óptimos
| Algoritmos Ávidos |
Los algoritmos ávidos o voraces (Greedy Algorithms) son algoritmos que toman decisiones de corto alcance, basadas en información inmediatamente disponible, sin importar consecuencias futuras.
Suelen ser bastante simples y se emplean sobre todo para resolver problemas de optimización, como por ejemplo, encontrar la secuencia óptima para procesar un conjunto de tareas por un computador, hallar el camino mínimo de un grafo, etc.
Habitualmente, los elementos que intervienen son:
- un conjunto o lista de candidatos (tareas a procesar, vértices del grafo, etc.);
- un conjunto de decisiones ya tomadas (candidatos ya escogidos);
- una función que determina si un conjunto de candidatos es una solución al problema (aunque no tiene por qué ser la óptima);
- una función que determina si un conjunto es completable, es decir, si añadiendo a este conjunto nuevos candidatos es posible alcanzar una solución al problema, suponiendo que esta exista;
- una función de selección que escoge el candidato aún no seleccionado que es más prometedor;
- una función objetivo que da el valor/coste de una solución (tiempo total del proceso, la longitud del camino, etc.) y que es la que se pretende maximizar o minimizar;
Para resolver el problema de optimización hay que encontrar un conjunto de candidatos que optimiza la función objetivo. Los algoritmos voraces proceden por pasos.
Inicialmente el conjunto de candidatos es vacío. A continuación, en cada paso, se intenta añadir al conjunto el mejor candidato de los aún no escogidos, utilizando la función de selección. Si el conjunto resultante no es completable, se rechaza el candidato y no se le vuelve a considerar en el futuro. En caso contrario, se incorpora al conjunto de candidatos escogidos y permanece siempre en él. Tras cada incorporación se comprueba si el conjunto resultante es una solución del problema. Un algoritmo voraz es correcto si la solución así encontrada es siempre óptima.
El esquema genérico del algoritmo voraz es:
funcion voraz(C:conjunto):conjunto
{ C es el conjunto de todos los candidatos }
S <= vacío { S es el conjunto en el que se construye la solución
mientras ¬solución(S) y C <> vacío hacer
x ¬ el elemento de C que maximiza seleccionar(x)
C ¬ C \ {x}
si completable(S U {x}) entonces S ¬ S U {x}
si solución(S)
entonces devolver S
si no devolver no hay solución
El nombre voraz proviene de que, en cada paso, el algoritmo escoge el mejor “pedazo” que es capaz de “comer” sin preocuparse del futuro. Nunca deshace una decisión ya tomada: una vez incorporado un candidato a la solución permanece ahí hasta el final; y cada vez que un candidato es rechazado, lo es para siempre.
Ejemplo: Mínimo número de monedas
Se desea pagar una cantidad de dinero a un cliente empleando el menor número posible de monedas. Los elementos del esquema anterior se convierten en:
- candidato: conjunto finito de monedas de, por ejemplo, 1, 5, 10 y 25 unidades, con una moneda de cada tipo por lo menos;
- solución: conjunto de monedas cuya suma es la cantidad a pagar;
- completable: la suma de las monedas escogidas en un momento dado no supera la cantidad a pagar;
- función de selección: la moneda de mayor valor en el conjunto de candidatos aún no considerados;
- función objetivo: número de monedas utilizadas en la solución.
| Método de Retroceso (backtracking) |
El Backtracking o vuelta atrás es una técnica de resolución general de problemas mediante una búsqueda sistemática de soluciones. El procedimiento general se basa en la descomposición del proceso de búsqueda en tareas parciales de tanteo de soluciones (trial and error).
Las tareas parciales se plantean de forma recursiva al construir gradualmente las soluciones. Para resolver cada tarea, se descompone en varias subtareas y se comprueba si alguna de ellas conduce a la solución del problema. Las subtareas se prueban una a una, y si una subtarea no conduce a la solución se prueba con la siguiente.
La descripción natural del proceso se representa por un árbol de búsqueda en el que se muestra como cada tarea se ramifica en subtareas. El árbol de búsqueda suele crecer rápidamente por lo que se buscan herramientas eficientes para descartar algunas ramas de búsqueda produciéndose la poda del árbol.
Diversas estrategias heurísticas, frecuentemente dependientes del problema, establecen las reglas para decidir en que orden se tratan las tareas mediante las que se realiza la ramificación del árbol de búsqueda, y qué funciones se utilizan para provocar la poda del árbol.
El método de backtracking se ajusta a muchos famosos problemas de la inteligencia artificial que admiten extensiones muy sencillas. Algunos de estos problemas son el de las Torres de Hanoi, el del salto del caballo o el de la colocación de las ocho reinas en el tablero de ajedrez, el problema del laberinto.
Un caso especialmente importante en optimización combinatoria es el problema de la selección óptima. Se trata del problema de seleccionar una solución por sus componentes, de forma que respetando una serie de restricciones, de lugar a la solución que optimiza una función objetivo que se evalúa al construirla. El árbol de búsqueda permite recorrer todas las soluciones para quedarse con la mejor de entre las que sean factibles. Las estrategias heurísticas orientan la exploración por las ramas más prometedoras y la poda en aquellas que no permiten alcanzar una solución factible o mejorar la mejor solución factible alcanzada hasta el momento.
El problema típico es el conocido como problema de la mochila. Se dispone de una mochila en la que se soporta un peso máximo P en la que se desean introducir objetos que le den el máximo valor. Se dispone de una colección de n objetos de los que se conoce su peso y su valor;
(pi,vi); i = 1, 2, …, n.
| Método de Branch and Bound |
Branch and bound (o también conocido como Ramifica y Poda) es una técnica muy similar a la de Backtracking, pues basa su diseño en el análisis del árbol de búsqueda de soluciones a un problema. Sin embargo, no utiliza la búsqueda en profundidad (depth first), y solamente se aplica en problemas de Optimización.
Los algoritmos generados por está técnica son normalmente de orden exponencial o peor en su peor caso, pero su aplicación ante instancias muy grandes, ha demostrado ser eficiente (incluso más que bactracking).
Se debe decidir de qué manera se conforma el árbol de búsqueda de soluciones. Sobre el árbol, se aplicará una búsqueda en anchura (breadth first), pero considerando prioridades en los nodos que se visitan (best first). El criterio de selección de nodos, se basa en un valor óptimo posible (bound), con el que se toman decisiones para hacer las podas en el árbol.
Modo de proceder de los algoritmos Branch and Bound:
- Nodo vivo: nodo con posibilidad de ser ramificado, es decir, no se ha realizado una poda.
- No se pueden comenzar las podas hasta que no se haya descendido a una hoja del árbol
- Se aplicará la poda a los nodos con una cota peor al valor de una solución dada à a los nodos podados a los que se les ha aplicado
una poda se les conoce como nodos muertos - Se ramificará hasta que no queden nodos vivos por expandir
- Los nodos vivos han de estar almacenados en algún sitio à lista de nodos, de modo que sepamos qué nodo expandir
Algoritmo General:
Función ramipoda(P:problema): solucion
L={P} (lista de nodos vivos)
S= ¥± (según se aplique máximo o mínimo)
Mientras L ¹ 0
n=nodo de mejor cota en L
si solucion(n)
si (valor(n) mejor que s)
s=valor(n)
para todo m Î L y Cota(m) peor que S
borrar nodo m de L
sino
añadir a L los hijos de n con sus cotas
borrar n de L (tanto si es solución como si ha ramificado)
Fin_mientras
Devolver S
