
Bueno, llegamos a la séptima parte y aún no vemos el horizonte. Espero les sirva a todos.
En cualquier estructura de datos puede plantearse la necesidad de saber si un cierto dato está almacenado en ella, y en su caso en que posición se encuentra. Es el problema de la búsqueda.
Existen diferentes métodos de búsqueda, todos parten de un esquema iterativo, en el cual se trata una parte o la totalidad de la estructura de datos sobre la que se busca.
El tipo de estructura condiciona el proceso de búsqueda debido a los diferentes modos de acceso a los datos.
Búsqueda Lineal
La búsqueda es el proceso de localizar un registro (elemento) con un valor de llave particular. La búsqueda termina exitosamente cuando se localiza el registro que contenga la llave buscada, o termina sin éxito, cuando se determina que no aparece ningún registro con esa llave.
Búsqueda lineal, también se le conoce como búsqueda secuencial. Supongamos una colección de registros organizados como una lista lineal. El algoritmo básico de búsqueda lineal consiste en empezar al inicio de la lista e ir a través de cada registro hasta encontrar la llave indicada (k), o hasta al final de la lista. Posteriormente hay que comprobar si ha habido éxito en la búsqueda.
Es el método más sencillo en estructuras lineales. En estructuras ordenadas el proceso se optimiza, ya que al llegar a un dato con número de orden mayor que el buscado, no hace falta seguir.
La situación óptima es que el registro buscado sea el primero en ser examinado. El peor caso es cuando las llaves de todos los n registros son comparados con k (lo que se busca). El caso promedio es n/2 comparaciones.
Este método de búsqueda es muy lento, pero si los datos no están en orden es el único método que puede emplearse para hacer las búsquedas. Si los valores de la llave no son únicos, para encontrar todos los registros con una llave particular, se requiere buscar en toda la lista.
Mejoras en la eficiencia de la búsqueda lineal:
- Muestreo de acceso: Este método consiste en observar que tan frecuentemente se solicita cada registro y ordenarlos de acuerdo a las probabilidades de acceso detectadas.
- Movimiento hacia el frente: Este esquema consiste en que la lista de registros se reorganicen dinámicamente. Con este método, cada vez que búsqueda de una llave sea exitosa, el registro correspondiente se mueve a la primera posición de la lista y se recorren una posición hacia abajo los que estaban antes que él.
- Transposición: Este es otro esquema de reorganización dinámica que consiste en que, cada vez que se lleve a cabo una búsqueda exitosa, el registro correspondiente se intercambia con el anterior. Con este procedimiento, entre más accesos tenga el registro, más rápidamente avanzará hacia la primera posición. Comparado con el método de movimiento al frente, el método requiere m ás tiempo de actividad para reorganizar al conjunto de registros. Una ventaja de método de transposición es que no permite que el requerimiento aislado de un registro, cambie de posición todo el conjunto de registros. De hecho, un registro debe ganar poco a poco su derecho a alcanzar el inicio de la lista.
- Ordenamiento: Una forma de reducir el número de comparaciones esperadas cuando hay una significativa frecuencia de búsqueda sin éxito es la de ordenar los registros en base al valor de la llave. Esta técnica es útil cuando la lista es una lista de excepciones, tales como una lista de decisiones, en cuyo caso la mayoría de las búsquedas no tendrán éxito. Con este método una búsqueda sin éxito termina cuando se encuentra el primer valor de la llave mayor que el buscado, en lugar
de la final de la lista.
En ciertos casos se desea localizar un elemento concreto de un arreglo. En una búsqueda lineal de un arreglo, se empieza con la primera casilla del arreglo y se observa una casilla tras otra hasta que se encuentra el elemento buscado o se ha visto todas las casillas. Como el resultado de la búsqueda es un solo valor, ya sea la posición del elemento buscado o cero, puede usarse una función para efectuar la búsqueda.
En la función BUSQ_LINEAL, nótese el uso de la variable booleana encontrada.
Function BUSQ_LINEAL (nombres: tiponom; Tam: integer; {Regresa el índice de la c elda que contiene el elemento buscado o regresa 0 si no está en el arreglo}
Var encontrado: boolean;
indice; integer:
Begin
encontrado := false;
indice := 1:
Reapeat
If nombres {índice} = sebusca then
begin
encontrado : = true;
BUSQ_LINEAL := indice
end
else
indice := indice + 1
Until (encontrado) or {indice > tam);
If not encontrado then BUSQ_LINEAL: = 0
End;
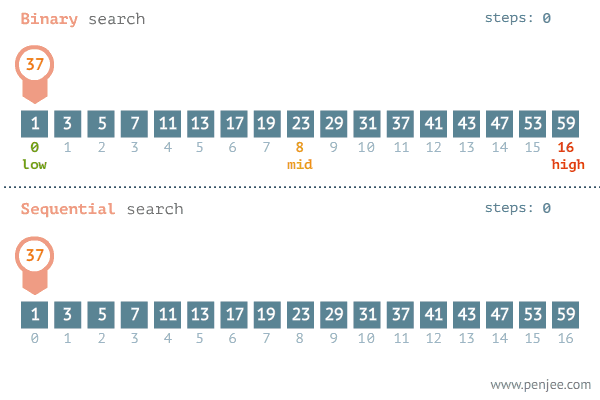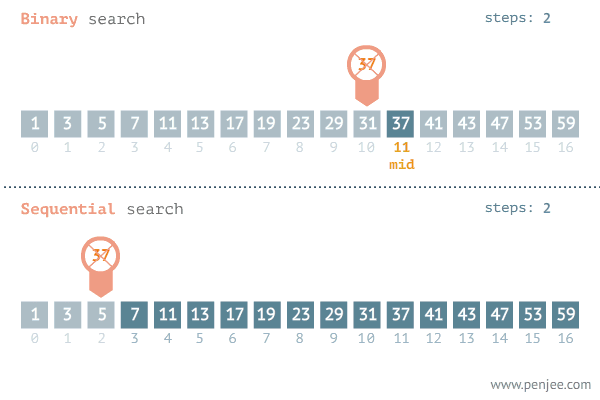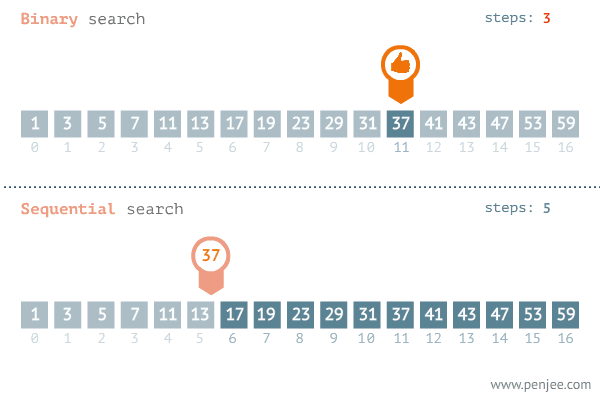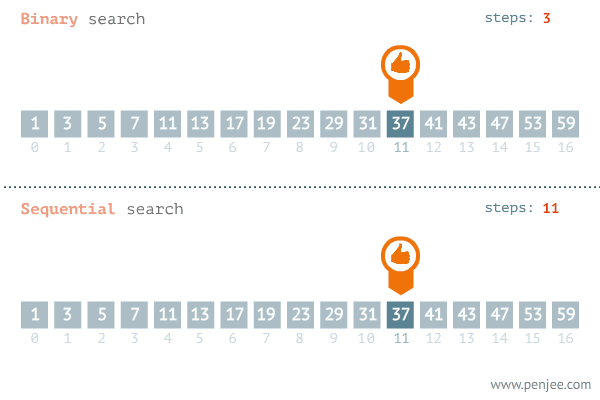
Búsqueda Binaria
Una búsqueda lineal funciona bastante bien para una lista pequeña. Pero si se desea buscar el número de teléfono de Jorge Perez en el directorio telefónico de Santiago, no sería sensato empezar con el primer nombre y continuar la búsqueda nombre por nombre. En un método más eficiente se aprovechará el orden alfabético de los nombres para ir inmediatamente a un lugar en la segunda mitad del directorio.
La búsqueda binaria es semejante al método usado automáticamente al buscar un número telefónico. En la búsqueda binaria se reduce sucesivamente la operación eliminando repetidas veces la mitad de la lista restante. Es claro que para poder realizar una búsqueda binaria debe tenerse una lista ordenada.
Se puede aplicar tanto a datos en listas lineales como en árboles binarios de búsqueda. Los prerrequisitos principales para la búsqueda binaria son:
- La lista debe estar ordenada en un orden especifíco de acuerdo al valor de la llave.
- Debe conocerse el número de registros.
Algoritmo:
- Se compara la llave buscada con la llave localizada al centro del arreglo.
- Si la llave analizada corresponde a la buscada fin de búsqueda si no.
- Si la llave buscada es menor que la analizada repetir proceso en mitad superior, sino en la mitad inferior.
- El proceso de partir por la mitad el arreglo se repite hasta encontrar el registro o hasta que el tamaño de la lista restante sea cero , lo cual implica que el valor de la llave buscada no está en la lista.
El esfuerzo máximo para este algoritmo es de log2 n. El mínimo de 1 y en promedio ½ log2 n.
Árboles de Búsqueda
Son tipos especiales de árboles que los hacen adecuados para almacenar y recuperar información. Como en un árbol binario de búsqueda buscar información requiere recorrer un solo camino desde la raíz a una hoja. Como en un árbol balanceado el más largo camino de la raíz a una hoja es O(log n). A diferencia de un árbol binario cada nodo puede contener varios
elementos y tener varios hijos. Debido a esto y a que es balanceado, permite acceder a grandes conjuntos de datos por caminos cortos.
Búsqueda por Transformación de Claves (Hashing)
Hasta ahora las técnicas de localización de registros vistas, emplean un proceso de búsqueda que implica cierto tiempo y esfuerzo. El siguiente método nos permite encontrar directamente el registro buscado.
La idea básica de este método consiste en aplicar una función que traduce un conjunto de posibles valores llave en un rango de direcciones relativas. Un problema potencial encontrado en este proceso, es que tal función no puede ser uno a uno; las direcciones calculadas pueden no ser todas únicas, cuando R(k1)= R(k2 ) . Pero: K1 diferente de K2 decimos que hay una colisión. A dos llaves diferentes que les corresponda la misma dirección relativa se les llama sinónimos.
A las técnicas de cálculo de direcciones también se les conoce como:
- Técnicas de almacenamiento disperso
- Técnicas aleatorias
- Métodos de transformación de llave-a-dirección
- Técnicas de direccionamiento directo
- Métodos de tabla Hash
- Métodos de Hashing
Pero el término más usado es el de hashing. Al cálculo que se realiza para obtener una dirección a partir de una llave se le conoce como función hash.
Ventajas:
- Se pueden usar los valores naturales de la llave, puesto que se traducen internamente a direcciones fáciles de localizar.
- Se logra independencia lógica y física, debido a que los valores de las llaves son independientes del espacio de direcciones.
- No se requiere almacenamiento adicional para los índices.
Desventajas:
- No pueden usarse registros de longitud variable.
- El archivo no está ordenado.
- No permite llaves repetidas.
- Solo permite acceso por una sola llave.
Costos:
- Tiempo de procesamiento requerido para la aplicación de la función hash.
- Tiempo de procesamiento y los accesos E/S requeridos para solucionar las colisiones.
La eficienciade una función hash depende de:
- La distribución de los valores de llave que realmente se usan.
- El número de valores de llave que realmente están en uso con respecto al tamaño del espacio de direcciones.
- El número de registros que pueden almacenarse en una dirección dada sin causar una colisión.
- La técnica usada para resolver el problema de las colisiones.
Las funciones hash más comunes son:
- Residuo de la división
- Método de la Multiplicación
- Medio del cuadrado
- Pliegue
Hashing por Residuo de la División
En este caso, h(k) = k mod m , en que m = número primo no muy cercano a una potencia de 2—si m = 2p, entonces h(k) es los p bits menos significativos de k.
La idea de este método es la de dividir el valor de la llave entre un número apropiado, y después utilizar el residuo de la división como dirección relativa para el registro (dirección = llave mod divisor).
Mientras que el valor calculado real de una dirección relativa, dados tanto un valor de llave como el divisor, es directo; la elección del divisor apropiado puede no ser tan simple. Existen varios factores que deben considerarse para seleccionar el divisor:
- El rango de valores que resultan de la operación “llave mod divisor”, va desde cero hasta el divisor 1. Luego, el divisor determina el tamaño del espacio de direcciones relativas. Si se sabe que el archivo va a contener por lo menos n registros, entonces tendremos que hacer que divisor > n, suponiendo que solamente un registro puede ser almacenado en una
dirección relativa dada. - El divisor deberá seleccionarse de tal forma que la probabilidad de colisión sea minimizada. ¿Cómo escoger este número? Mediante investigaciones se ha demostrado que los divisores que son números pares tienden a comportase pobremente, especialmente con los conjuntos de valores de llave que son predominantemente impares. Algunas investigaciones sugieren que el divisor deberá ser un número primo. Sin embargo, otras sugieren que los divisores no primos trabajan tan bién como los divisores primos, siempre y cuando los divisores no primos no contengan ningún factor primo menor de 20. Lo más común es elegir el número primo más próximo al total de direcciones.
Independientemente de que tan bueno sea el divisor, cuando el espacio de direcciones de un archivo está completamente lleno, la probabilidad de colisión crece dramáticamente. La saturación de archivo de mide mediante su factor de carga , el cual se define como la relación del número de registros en el archivo contra el número de registros que el archivo podría
contener si estuviese completamente lleno.
Todas las funciones hash comienzan a trabajar probablemente cuando el archivo está casi lleno. Por lo general, el máximo factor de carga que puede tolerarse en un archivo para un rendimiento razonable es de entre el 70% y 80%.
Por ejemplo, si:
- n = 2,000 strings de caracteres de 8 bits, en que cada string es interpretado como un número entero k en base 256, y
- estamos dispuestos a examinar un promedio de 3 elementos en una búsqueda fallida,
Entonces podemos:
- asignar una tabla de mezcla de tamaño m = 701 y
- usar la función de mezcla k(k) = k mod 701 .
Hashing por Método de la Multiplicación
En este caso, h(k) = ëm (k A mod 1) û , en que 0 < A < 1; el valor de m no es crítico y típicamente se usa una potencia de 2 para facilitar el cálculo computacional de la función.
Por ejemplo, si k = 123456, m = 10,000, y A = ( 5 – 1)/2 » 0.6180339887, entonces h(k) = 41.
Hashing por Medio del Cuadrado
En esta técnica, la llave es elevada al cuadrado, después algunos dígitos específicos se extraen de la mitad del resultado para constituir la dirección relativa. Si se desea una dirección de n dígitos, entonces los dígitos se truncan en ambos extremos de la llave elevada al cuadrado, tomando n dígitos intermedios. Las mismas posiciones de n dígitos deben extraerse para cada llave.
Ejemplo:
Utilizando esta función hashing el tamaño del archivo resultante es de 10n donde n es el numero de dígitos extraídos de los valores de la llave elevada al cuadrado.
Hashing por Pliegue
En esta técnica el valor de la llave es particionada en varias partes, cada una de las cuales (excepto la última) tiene el mismo número de dígitos que tiene la dirección relativa objetivo. Estas particiones son después plegadas una sobre otra y sumadas. El resultado, es la dirección relativa. Igual que para el método del medio del cuadrado, el tamaño del espacio de direcciones
relativas es una potencia de 10.
Comparación entre las Funciones Hash
Aunque alguna otra técnica pueda desempeñarse mejor en situaciones particulares, la técnica del residuo de la división proporciona el mejor desempeño. Ninguna función hash se desempeña siempre mejor que las otras. El método del medio del cuadrado puede aplicarse en archivos con factores de cargas bastantes bajas para dar generalmente un buen desempeño. El método de pliegues puede ser la técnica más fácil de calcular, pero produce resultados bastante erráticos, a menos que la longitud de la llave sea aproximadamente igual a la longitud de la dirección.
Si la distribución de los valores de llaves no es conocida, entonces el método del residuo de la división es preferible. Note que el hashing puede ser aplicado a llaves no numéricas. Las posiciones de ordenamiento de secuencia de los caracteres en un valor de llave pueden ser utilizadas como sus equivalentes “numéricos”. Alternativamente, el algoritmo hash actúa
sobre las representaciones binarias de los caracteres.
Todas las funciones hash presentadas tienen destinado un espacio de tamaño fijo. Aumentar el tamaño del archivo relativo creado al usar una de estas funciones, implica cambiar la función hash, para que se refiera a un espacio mayor y volver a cargar el nuevo archivo.
See you!!
