
Desde las primeras computadoras modernas que se ha metido en el imaginario del ser humano la idea de que una máquina computacional no sólo debe entendernos, sino entender el mundo que la rodea.
Y una forma de lograrlo sería teniendo una visión parecida a la nuestra.
Así, el usar software para tratar de comprender el mundo visual ha sido y sigue siendo uno de los grandes desafíos del rubro.
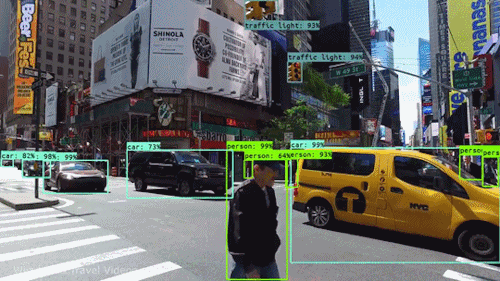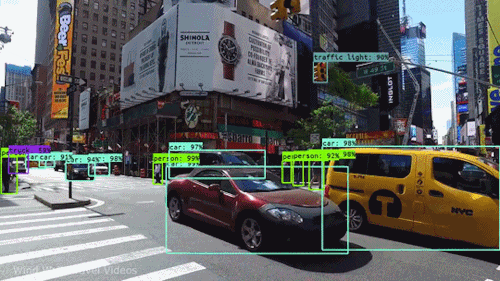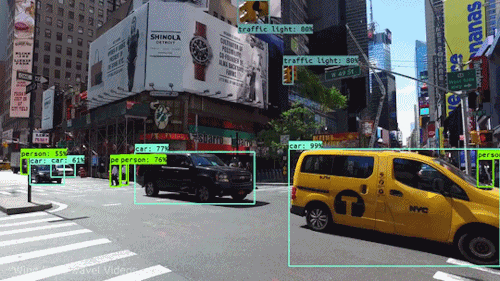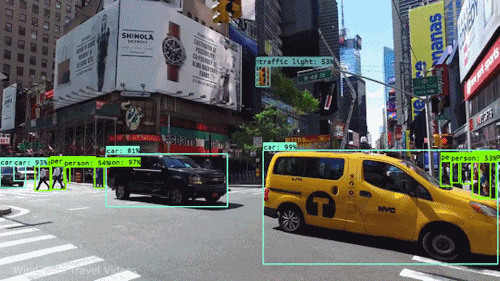
La llamada visión por computadora (o Computer Visión) es el proceso de usar “máquinas” para entender y analizar imágenes (fotos y videos). Y mientras que estos algoritmos de reconocimiento han estado dando vueltas en varias formas desde mediados de la década del 60 del siglo pasado, los recientes avances en machine learning y deep learning, el aumento extraordinario de espacio y dispositivos de almacenamiento, la capacidades y velocidades de procesamiento y la gran cantidad de dispositivos de entrada baratos disponibles (desde cualquier celular de gama baja o hasta un escáner de bolsillo bien barato sirven); han llevado a mejoras significativas en qué tan bien nuestro software puede explorar y reconocer este tipo de contenido.
La visión por computadora es el nombre general que abarca muchas técnicas computacionales que involucran en mayor o menor escala imágenes, videos, iconografía, o cualquier cosa con píxeles y su modo de tratamiento o procesamiento.
Con esto en mente, existen algunas tareas específicas que se toman como cimientos:
- en la clasificación de objetos, se requiere un modelo donde se puedan clasificar objetos nuevos mediante un dataset de objetos específicos ya ingresado, es decir, que el sistema pueda reconocer un auto aunque este no exista en su base de datos, pero sí modelos de autos semejantes.
- En la identificación de objetos, donde se reconocerá una instancia específica de un objeto, por ejemplo reconocer que dos caras son distintas, una siendo la mía y la otra la de Guido Kazca.
Acomodemos todo, las computadoras interpretan las imágenes de manera muy simple: como una serie de píxeles, cada uno con su propio set de valores de color.
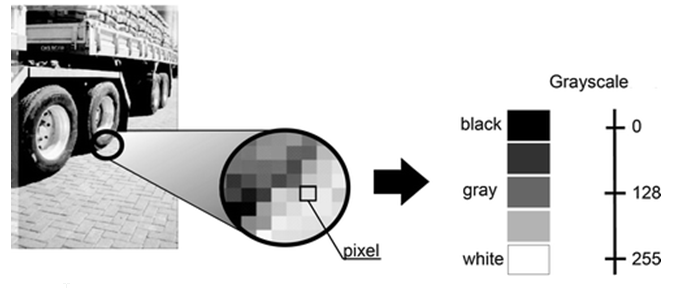
Pensemos una imagen como una grilla gigante de cuadrados (nuestros pixeles). Estos a su vez se representan por lo general por una o más series de números. Por ejemplo para imágenes en escala de grises es suficiente un valor entre 0 y 255 que nos indicará cuanto negro en ese pixel (o cuanto blanco) hay. Otro ejemplo es si tomamos una imagen color y la representamos mediante los colores RGB (red-green-blue, rojo-verde-azul), tres valores que estarán entre 0 y 255...
Computacionalmente hablando esto es caro, miremos:
- Cada valor de cada color “primario” se guarda en 8 bits
- 8 bits X 3 colores por pixel = 24 bits per pixel.
- una imagen normal de 1024 x 768 x 24 bits per pixel = caso 19 millones de bits, o alrededor de 2.36 megabytes.
Ya es mucha memoria para una sola imagen, y muchos píxeles para que un algoritmo lo trabaje. Y ni hablar si es un video o captura de imágenes en tiempo real como vamos a ver que se intenta hacer en los vehículos. Lo algoritmos de Deep Learning han facilitado muchas de estas cosas, especialmente con el uso de redes neuronales que tratan de imitar (muy pobremente aún) las interconexiones de nuestras neuronas.
Y por eso recién ahora la estamos viendo aplicada más cotidianamente. El reconocimiento de nombres y números de calles en los mapas de Google, o el desbloqueo de Facebook con el rostro son aplicaciones que ya integramos a nuestras vidas sin darnos cuenta.
Los rovers marcianos “Curiosity” y “Opportunity” operan basados en la visión por computadora; el “Opportunity” lo viene haciendo por más de 10 años. Aquí se apuntó a que los datos “entregados” por la visión por computadora fueran suficientes para que el rover pudiera desenvolverse sin direcciones humanas.

Es para destacar que nada es muy nuevo igualmente, Ford, la compañía de manufactura de autos como el fantástico Mustang, ha estado en constante investigación de eso prácticamente desde comienzo del 1900, buscando la forma de volver más autónomos a sus vehículos. Para esta época mucha de la tecnología que subyace debajo de los vehículos autónomos (vehículos que pueden “manejarse solos”) descansa sobre el análisis de múltiples canales de captura de video que la computadora de abordo del auto tiene que analizar para elegir su curso de acción.

La próxima semana seguimos