

Sexta parte ya acerca de esta “breve” introducción a los algoritmos… Espero les sirva, y aunque no, no deja de ser interesante.
DEFINICIÓN
- Entrada:
- Una secuencia de n números <a1, a2 , …, an>, usualmente en la forma de un arreglo de n elementos.
- Una secuencia de n números <a1, a2 , …, an>, usualmente en la forma de un arreglo de n elementos.
- Salida:
- Una permutación <a’1, a’2, …, a’n> de la secuencia de entrada tal que a’1 = a’2 = … = a’n.
CONSIDERACIONES:
Cada número es normalmente una clave que forma parte de un registro; cada registro contiene además datos satélites que se
mueven junto con la clave; si cada registro incluye muchos datos satélites, entonces movemos punteros a los registros (y no los registros).
Un método de ordenación se denomina estable si el orden relativo de los elementos no se altera por el proceso de ordenamiento. (Importante cuanto se ordena por varias claves).
Hay dos categorías importantes y disjuntas de algoritmos de ordenación:
- Ordenación interna: La cantidad de registros es suficientemente pequeña y el proceso puede llevarse a cabo en memoria.
- Ordenación externa: Hay demasiados registros para permitir ordenación interna; deben almacenarse en disco.
Por ahora nos ocuparemos sólo de ordenación interna.
Los algoritmos de ordenación interna se clasifican de acuerdo con la cantidad de trabajo necesaria para ordenar una secuencia de n elementos:
¿Cuántas comparaciones de elementos y cuántos movimientos de elementos de un lugar a otro son necesarios?
Empezaremos por los métodos tradicionales (inserción y selección). Son fáciles de entender, pero ineficientes, especialmente para juegos de datos grandes. Luego prestaremos más atención a los más eficientes: heapsort y quicksort.
| Ordenamiento por Inserción |
Este es uno de los métodos más sencillos. Consta de tomar uno por uno los elementos de un arreglo y recorrerlo hacia su posición con respecto a los anteriormente ordenados. Así empieza con el segundo elemento y lo ordena con respecto al primero. Luego sigue con el tercero y lo coloca en su posición ordenada con respecto a los dos anteriores, así sucesivamente hasta recorrer todas las posiciones del arreglo.
Este es el algoritmo:
Sea n el número de elementos en el arreglo A.
INSERTION-SORT(A) :
{Para cada valor de j, inserta A[j] en la posición que le corresponde en la secuencia ordenada A[1 .. j – 1]}

Análisis del algoritmo:
Número de comparaciones: n(n-1)/2 lo que implica un T(n) = O(n2 ). La ordenación por inserción utiliza aproximadamente n2/4 comparaciones y n2/8 intercambios en el caso medio y dos veces más en el peor de los casos. La ordenación por inserción es lineal para los archivos casi ordenados.
| Ordenamiento por Selección |
El método de ordenamiento por selección consiste en encontrar el menor de todos los elementos del arreglo e intercambiarlo con el que está en la primera posición. Luego el segundo más pequeño, y así sucesivamente hasta ordenar todo el arreglo.
SELECTION-SORT(A) :
{Para cada valor de j, selecciona el menor elemento de la secuencia no ordenada A[j .. n] y lo intercambia con A[j]}
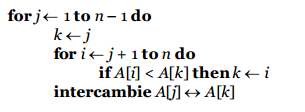
Análisis del algoritmo:
La ordenación por selección utiliza aproximadamente n2/2 comparaciones y n intercambios, por lo cual T(n) = O(n2 ).
| Ordenamiento Burbuja (BubbleSort) |
El algoritmo bubblesort, también conocido como ordenamiento burbuja, funciona de la siguiente manera: Se recorre el arreglo intercambiando los elementos adyacentes que estén desordenados. Se recorre el arreglo tantas veces hasta que ya no haya cambios que realizar. Prácticamente lo que hace es tomar el elemento mayor y lo va recorriendo de posición en posición hasta
ponerlo en su lugar.
Procedimiento BubbleSort:

Análisis del algoritmo:
La ordenación de burbuja tanto en el caso medio como en el peor de los casos utiliza aproximadamente n2/2 comparaciones y n2/2 intercambios, por lo cual T(n) = O(n2)
| Ordenamiento Rápido (QuickSort) |
Vimos que en un algoritmo de ordenamiento por intercambio, son necesarios intercambios de elementos en sublistas hasta que no son posibles más. En el burbujeo, son comparados ítems correlativos en cada paso de la lista. Por lo tanto para ubicar un ítem en su correcta posición, pueden ser necesarios varios intercambios.
Veremos el sort de intercambio desarrollado por C.A.R. Hoare conocido como Quicksort. Es más eficiente que el burbujeo (bubblesort) porque los intercambios involucran elementos que están más apartados, entonces menos intercambios son requeridos para poner un elemento en su posición correcta.
La idea básica del algoritmo es elegir un elemento llamado pivote, y ejecutar una secuencia de intercambios tal que todos los elementos menores que el pivote queden a la izquierda y todos los mayores a la derecha.
Lo único que requiere este proceso es que todos los elementos a la izquierda sean menores que el pivote y que todos los de la derecha sean mayores luego de cada paso, no importando el orden entre ellos, siendo precisamente esta flexibilidad la que hace eficiente al proceso.
Hacemos dos búsquedas, una desde la izquierda y otra desde la derecha, comparando el pivote con los elementos que vamos recorriendo, buscando los menores o iguales y los mayores respectivamente.
DESCRIPCIÓN
Basado en el paradigma dividir-y-conquistar, estos son los tres pasos para ordenar un subarreglo A[p … r]:
Dividir. El arreglo A[p … r] es particionado en dos subarreglos no vacíos A[p … q] y A[q+1 … r]—cada dato de A[p … q] es menor que cada dato de A[q+1 … r]; el índice q se calcula como parte de este proceso de partición.
Conquistar. Los subarreglos A[p … q] y A[q+1 … r] son ordenados mediante sendas llamadas recursivas a QUICKSORT.
Combinar. Ya que los subarreglos son ordenados in situ, no es necesario hacer ningún trabajo extra para combinarlos; todo el arreglo A[p … r] está ahora ordenado.

Para ordenar un arreglo completo A, la llamada inicial es QUICKSORT(A, 1, n).
PARTITION reordena el subarreglo A[p … r] in situ, poniendo datos menores que el pivote x = A[p] en la parte baja del arreglo y datos mayores que x en la parte alta.
Análisis del algoritmo:
Depende de si la partición es o no balanceada, lo que a su vez depende de cómo se elige los pivotes:
- Si la partición es balanceada, QUICKSORT corre asintóticamente tan rápido como ordenación por mezcla.
- Si la partición es desbalanceada, QUICKSORT corre asintóticamente tan lento como la ordenación por inserción.
El peor caso ocurre cuando PARTITION produce una región con n–1 elementos y otra con sólo un elemento. Si este desbalance se presenta en cada paso del algoritmo, entonces, como la partición toma tiempo Θ(n) y σ(1) = Θ(1), tenemos la recurrencia:
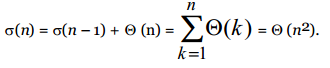
Por ejemplo, este tiempo Θ(n2) de ejecución ocurre cuando el arreglo está completamente ordenado, situación en la cual INSERTIONSORT corre en tiempo O(n).
Si la partición produce dos regiones de tamaño n/2, entonces la recurrencia es:
σ(n) = 2σ(n/2) + Θ(n) = Θ(n log n).
Tenemos un algoritmo mucho más rápido cuando se da el mejor caso de PARTITION. El caso promedio de QUICKSORT es mucho más parecido al mejor caso que al peor caso; por ejemplo, si PARTITION siempre produce una división de proporcionalidad 9 a 1:
- Tenemos la recurrencia σ(n) = σ(9n/10) + σ(n/10) + n.
- En el árbol de recursión, cada nivel tiene costo n (o a lo más n más allá de la profundidad log10n), y la recursión termina en la
profundidad log10/9n = Θ(log n) … ⇒ - … el costo total para divisiones 9 a 1 es Θ(nlog n), asintóticamente lo mismo que para divisiones justo en la mitad.
- Cualquier división de proporcionalidad constante, por ejemplo, 99 a 1, produce un árbol de recursión de profundidad Θ(log n), en que el costo de cada nivel es Θ(n), lo que se traduce en que el tiempo de ejecución es Θ(nlog n).
En la práctica, en promedio, PARTITION produce una mezcla de divisiones buenas y malas, que en el árbol de recursión están distribuidas aleatoriamente; si suponemos que aparecen alternadamente por niveles:
- En la raíz, el costo de la partición es n y los arreglos producidos tienen tamaños n–1 y 1.
- En el siguiente nivel, el arreglo de tamaño n–1 es particionado en dos arreglos de tamaño (n–1)/2, y el costo de procesar un arreglo de tamaño 1 es 1.
- Esta combinación produce tres arreglos de tamaños 1, (n–1)/2 y (n– 1)/2 a un costo combinado de 2n–1 = Θ(n) …
- … no peor que el caso de una sola partición que produce dos arreglos de tamaños (n–1)/2 + 1 y (n–1)/2 a un costo de n = Θ(n), y que es muy aproximadamente balanceada.
Intuitivamente, el costo Q(n) de la división mala es absorbido por el costo Θ(n) de la división buena:
⇒ la división resultante es buena.
⇒ El tiempo de ejecución de QUICKSORT, cuando los niveles producen alternadamente divisiones buenas y malas, es como el tiempo de ejecución para divisiones buenas únicamente:
O(n log n), pero con una constante más grande.
| Ordenamiento por Montículo (HeapSort) |
DEFINICIONES
Un heap (binario) es un arreglo que puede verse como un árbol binario completo:
- Cada nodo del árbol corresponde a un elemento del arreglo;
- El árbol está lleno en todos los niveles excepto posiblemente el de más abajo, el cual está lleno desde la izquierda hasta un cierto punto.
Un arreglo A que representa a un heap tiene dos atributos:
- λ[A] es el número de elementos en el arreglo;
- σ[A] es el número de elementos en el heap almacenado en el arreglo — σ[A] = λ[A];
- A[1 .. λ[A]] puede contener datos válidos, pero ningún dato más allá de A[σ [A]] es un elemento del heap.
La raíz del árbol es A[1]; y dado el índice i de un nodo, los índices de su padre, hijo izquierdo, e hijo derecho se calculan como:
P(i) : return ⌊i/2⌋ L(i) : return 2i R(i) : return 2i + 1
Un heap satisface la propiedad de heap:
- Para cualquier nodo i distinto de la raíz, A[P(i)] = A[i];
- El elemento más grande en un heap está en la raíz;
- Los subárboles que tienen raíz en un cierto nodo contienen valores más pequeños que el valor contenido en tal nodo.
La altura de un heap de n elementos es Θ(log n).
RESTAURACIÓN DE LA PROPIEDAD DE HEAP
Consideremos un arreglo A y un índice i en el arreglo, tal que:
- Los árboles binarios con raíces en L(i) y R(i) son heaps;
- A[i] puede ser más pequeño que sus hijos, violando la propiedad de heap.
HEAPIFY hace “descender” por el heap el valor en A[i], de modo que el subárbol con raíz en i se vuelva un heap; en cada paso:
- determinamos el más grande entre A[i], A[L(i)] y A[R(i)], y almacenamos su índice en k;
- si el más grande no es A[i], entonces intercambiamos A[i] con A[k], de modo que ahora el nodo i y sus hijos satisfacen la propiedad de heap;
- pero ahora, el nodo k tiene el valor originalmente en A[i]—el subárbol con raíz en k podría estar violando la propiedad de heap …
- … siendo necesario llamar a HEAPIFY recursivamente.

El tiempo de ejecución de HEAPIFY a partir de un nodo de altura h es O(h) = O(log n), en que n es el número de nodos en el subárbol con raíz en el nodo de partida.
CONSTRUCCIÓN DE UN HEAP
Usamos HEAPIFY de abajo hacia arriba para convertir un arreglo A[1 .. n]— n = l[A] —en un heap:
- Como los elementos en A[(⌊n/2⌋ + 1) .. n] son todos hojas del árbol, cada uno es un heap de un elemento;
- BUILD-HEAP pasa por los demás nodos del árbol y ejecuta HEAPIFY en cada uno.
- El orden en el cual los nodos son procesados garantiza que los subárboles con raíz en los hijos del nodo i ya son heaps cuando HEAPIFY es ejecutado en el nodo i.

El tiempo que toma HEAPIFY al correr en un nodo varía con la altura del nodo, y las alturas de la mayoría de los nodos son pequeñas. En un heap de n elementos hay a lo más n/2h+1 nodos de altura h, de modo que el costo total de BUILD-HEAP es:

Un heap es un árbol binario con las siguientes características:
- Es completo. Cada nivel es completo excepto posiblemente el último, y en ese nivel los nodos están en las posiciones más a la izquierda.
- Los ítems de cada nodo son mayores e iguales que los ítems almacenados en los hijos.
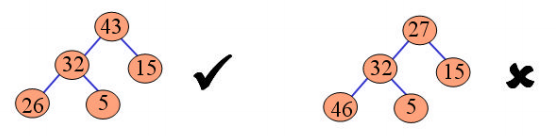
Para implementarlo podemos usar estructuras enlazadas o vectores numerando los nodos por nivel y de derecha a izquierda. Es decir:

De este modo, es fácil buscar la dirección del padre o de los hijos de un nodo. El padre de i es: i div 2. Los hijos de i son: 2 * i y 2 * i + 1.
Un algoritmo para convertir un árbol binario completo en un heap es básico para otras operaciones de heap. Por ejemplo un árbol en el que ambos subárboles son heap pero el árbol en si no lo es.
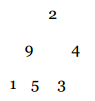
La única razón por la que no es un heap es porque la raíz es menor que uno (o dos como en este caso subárboles)El primer paso es intercambiar la raíz con el mayor de los dos hijos:

Esto garantiza que la nueva raíz sea mayor que ambos hijos, y que uno de estos siga siendo un heap (en este caso el derecho) y que el otro pueda ser o no. Si es, el árbol entero lo es, sino simplemente repetimos el swapdown en este subárbol.

Heapify: Recibe un Árbol Binario Completo (ABC) almacenado en un arreglo desde posición 1 a posición n. Convierte el árbol en un heap. SwapDown (árbol cuya raíz esta en r)
Veamos un ejemplo: Sean los siguientes elementos: 35, 15, 77, 60, 22, 41. El arreglo contiene los ítems como un ABC.

Usamos Heapify para convertirlo en Heap.
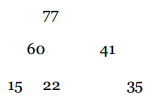
Esto pone al elemento más grande en la raíz, es decir la posición 1 del vector. Ahora usamos la estrategia de sort de selección y posicionamos correctamente al elemento más grande y pasamos a ordenar la sublista compuesta por los otros 5 elementos

En términos del árbol estamos cambiando, la raíz por la hoja más a la derecha. Sacamos ese elemento del árbol. El árbol que queda no es un heap. Como solo cambiamos la raíz, los subárboles son heaps, entonces podemos usar swapdown en lugar del Heapify que consume más tiempo.
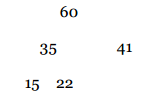
Ahora usamos la misma técnica de intercambiar la raíz con la hoja más a la derecha que podamos.

Volvemos a usar SwapDown para convertir en un Heap.

Y volvemos a hacer el intercambio hoja-raíz.

Volvemos a usar SwapDown

Finalmente, el árbol de dos elementos es convertido en un heap e intercambiado la raíz con la hoja y podado

El siguiente algoritmo resume el procedimiento descrito. Consideramos a X como un árbol binario completo (ABC) y usamos heapify para convertirlo en un heap.
For i = n down to 2 do
- Intercambiar X[1] y X[i], poniendo el mayor elemento de la sublista X[1]…X[i] al final de esta.
- Aplicar SwapDown para convertir en heap el árbol binario correspondiente a la sublista almacenada en las posiciones 1 a i – 1 de X.
| Otros Tipos de Ordenamiento |
Existen varios otros algoritmos de ordenamiento. A continuación se mencionarán brevemente algunos otros más.
Ordenamiento por Incrementos Decrecientes
Denominado así por su desarrollador Donald Shell (1959). El ordenamiento por incrementos decrecientes (o método shellsort) es una generalización del ordenamiento por inserción donde se gana rápidez al permitir intercambios entre elementos que se encuentran muy alejados.
La idea es reorganizar la secuencia de datos para que cumpla con la propiedad siguiente: si se toman todos los elementos separados a una distancia h, se obtiene una secuencia ordenada.
Se dice que la secuencia h ordenada está constituida por h secuencias ordenadas independendientes, pero entrelazadas entre sí. Se utiliza una serie decreciente h que termine en 1.
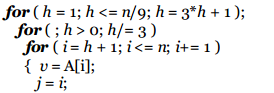
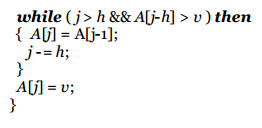
Análisis del algoritmo:
Esta sucesión de incrementos es fácil de utilizar y conduce a una ordenación eficaz. Hay otras muchas sucesiones que conducen a ordenaciones mejores. Es difícil mejorar el programa anterior en más de un 20%, incluso para n grande. Existen sucesiones desfavorables como por ejemplo: 64, 32, 16, 8, 4, 2, 1, donde sólo se comparan elementos en posiciones impares cuando h=1.
Nadie ha sido capaz de analizar el algoritmo, por lo que es difícil evaluar analíticamente los diferentes incrementos y su comparación con otros métodos, en consecuencia no se conoce su forma funcional del tiempo de ejecución.
Para la sucesión de incrementos anterior se tiene un T(n) = n( log n)2 y n1,25. La ordenación de Shell nunca hace más de n3 /2 comparaciones (para los incrementos 1,2,13, 40…..)
Ordenamiento por Mezclas Sucesivas (merge sort)
Se aplica la técnica divide-y-vencerás, dividiendo la secuencia de datos en dos subsecuencias hasta que las subsecuencias tengan un único elemento, luego se ordenan mezclando dos subsecuencias ordenadas en una secuencia ordenada, en forma sucesiva hasta obtener una secuencia única ya ordenada.
Si n = 1 solo hay un elemento por ordenar, sino se hace una ordenación de mezcla de la primera mitad del arreglo con la segunda mitad. Las dos mitades se ordenan de igual forma.
Ejemplo: Se tiene un arreglo de 8 elementos, se ordenan los 4 elementos de cada arreglo y luego se mezclan. El arreglo de 4 elementos, se ordenan los 2 elementos de cada arreglo y luego se mezclan. El arreglo de 2 elementos, como cada arreglo sólo tiene n = 1 elemento, solo se mezclan.


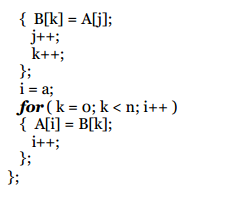
Análisis del algoritmo:
La relación de recurrencia del algoritmo es T(1) = 1, T(n) = 2 T(n/2) + n, cuya solución es T(n) = n log n.
