
La búsqueda se nos volvió un poco más complicada de analizar.
Métodos para Resolver el Problema de las Colisiones
Considere las llaves K1 y K2 que son sinónimas para la función hash R. Si K1 es almacenada primero en el archivo y su dirección es R(K1), entonces se dice que K1 esta almacenado en su dirección de origen.
Existen dos métodos básicos para determinar dónde debe ser alojado K2:
Direccionamiento abierto. Se encuentra entre dirección de origen para K2 dentro del archivo.
Separación de desborde (Área de desborde). Se encuentra una dirección para K2 fuera del área principal del archivo, en un área especial de desborde, que es utilizada exclusivamente para almacenar registro que no pueden ser asignados en su dirección de origen
Los métodos más conocidos para resolver colisiones son:
Sondeo lineal:
Es una técnica de direccionamiento abierto. Este es un proceso de búsqueda secuencial desde la dirección de origen para encontrar la siguiente localidad vacía. Esta técnica es también conocida como método de desbordamiento consecutivo.
Para almacenar un registro por hashing con sondeo lineal, la dirección no debe caer fuera del límite del archivo. En lugar de terminar cuando el límite del espacio de dirección se alcanza, se regresa al inicio del espacio y sondeamos desde ahí. Por lo que debe ser posible detectar si la dirección base ha sido encontrada de nuevo, lo cual indica que el archivo está lleno y
no hay espacio para la llave.
Para la búsqueda de un registro por hashing con sondeo lineal, los valores de llave de los registros encontrados en la dirección de origen, y en las direcciones alcanzadas con el sondeo lineal, deberá compararse con el valor de la llave buscada, para determinar si el registro objetivo ha sido localizado o no.
El sondeo lineal puede usarse para cualquier técnica de hashing. Si se emplea sondeo lineal para almacenar registros, también deberá emplearse para recuperarlos.
Doble hashing
En esta técnica se aplica una segunda función hash para combinar la llave original con el resultado del primer hash. El resultado del segundo hash puede situarse dentro del mismo archivo o en un archivo de sobreflujo independiente; de cualquier modo, será necesario algún método de solución si ocurren colisiones durante el segundo hash.
La ventaja del método de separación de desborde es que reduce la situación de una doble colisión, la cual puede ocurrir con el método de direccionamiento abierto, en el cual un registro que no está almacenado en su dirección de origen desplazará a otro registro, el que después buscará su dirección de origen. Esto puede evitarse con direccionamiento abierto,
simplemente moviendo el registro extraño a otra localidad y almacenando al nuevo registro en la dirección de origen ahora vacía.
Puede ser aplicado como cualquier direccionamiento abierto o técnica de separación de desborde. Para ambas métodos para la solución de colisiones existen técnicas para mejorar su desempeño como:
1 – Encadenamiento de sinónimos
Una buena manera de mejorar la eficiencia de un archivo que utiliza el cálculo de direcciones, sin directorio auxiliar para guiar la recuperación de registros, es el encadenamiento de sinónimos. Mantener una lista ligada de registros, con la misma dirección de origen, no reduce el número de colisiones, pero reduce los tiempos de acceso para recuperar los registros que no se encuentran en su localidad de origen. El encadenamiento de sinónimos puede emplearse con cualquier técnica de solución de colisiones. Cuando un registro debe ser recuperado del archivo, solo los sinónimos de la llave objetivo son accesados.
2 – Direccionamiento por cubetas
Otro enfoque para resolver el problema de las colisiones es asignar bloques de espacio (cubetas), que pueden acomodar ocurrencias múltiples de registros, en lugar de asignar celdas individuales a registros. Cuando una cubeta es desbordada, alguna nueva localización deberá ser encontrada para el registro. Los métodos para el problema de sobrecupo son básicamente los mismos que los métodos para resolver colisiones.
Comparación entre Sondeo Lineal y Doble Hashing
De ambos métodos resultan distribuciones diferentes de sinónimos en un archivo relativo. Para aquellos casos en que el factor de carga es bajo (< 0.5), el sondeo lineal tiende a agrupar los sinónimos, mientras que el doble hashing tiende a dispersar los sinónimos más ampliamente a través del espacio de direcciones.
El doble hashing tiende a comportarse casi también como el sondeo lineal con factores de carga pequeños (< 0.5), pero actúa un poco mejor para factores de carga mayores. Con un factor de carga > 80 %, el sondeo lineal, por lo general, resulta tener un comportamiento terrible, mientras que el doble hashing es bastante tolerable para búsquedas exitosas, pero no así en búsquedas no exitosas.
Búsqueda en Textos
La búsqueda de patrones en un texto es un problema muy importante en la práctica. Sus aplicaciones en computación son variadas, como por ejemplo la búsqueda de una palabra en un archivo de texto o problemas relacionados con biología computacional, en donde se requiere buscar patrones dentro de una secuencia de ADN, la cual puede ser modelada como una secuencia de caracteres (el problema es más complejo que lo descrito, puesto que se requiere buscar patrones en donde ocurren alteraciones con cierta probabilidad, esto es, la búsqueda no es exacta).
En este capítulo se considerará el problema de buscar la ocurrencia de un patrón dentro de un texto. Se utilizarán las siguientes convenciones: n denotará el largo del texto en donde se buscará el patrón, es decir, texto = a1 a2 … an. Donde m denotará el largo del patrón a buscar, es decir, patrón = b1 b2 … bm.
Por ejemplo:
Texto = “analisis de algoritmos” n=22 y m=4
Patrón = “algo”
Algoritmo de Fuerza Bruta
Se alinea la primera posición del patrón con la primera posición del texto, y se comparan los caracteres uno a uno hasta que se acabe el patrón, esto es, se encontró una ocurrencia del patrón en el texto, o hasta que se encuentre una discrepancia.

Si se detiene la búsqueda por una discrepancia, se desliza el patrón en una posición hacia la derecha y se intenta calzar el patrón nuevamente.
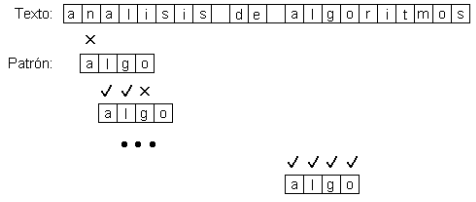
En el peor caso este algoritmo realiza O(m.n)comparaciones de caracteres.
Algorimo Knuth-Morris-Pratt
Suponga que se está comparando el patrón y el texto en una posición dada, cuando se encuentra una discrepancia.
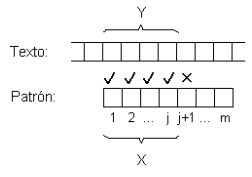
Sea X la parte del patrón que calza con el texto, e Y la correspondiente parte del texto, y suponga que el largo de X es j. El algoritmo de fuerza bruta mueve el patrón una posición hacia la derecha, sin embargo, esto puede o no puede ser lo correcto en el sentido que los primeros j-1 caracteres de X pueden o no pueden calzar los últimos j-1 caracteres de Y.
La observación clave que realiza el algoritmo Knuth-Morris-Pratt (en adelante KMP) es que X es igual a Y, por lo que la pregunta planteada en el párrafo anterior puede ser respondida mirando solamente el patrón de búsqueda, lo cual permite precalcular la respuesta y almacenarla en una tabla.
Por lo tanto, si deslizar el patrón en una posición no funciona, se puede intentar deslizarlo en 2, 3, …, hasta j posiciones.
Se define la función de fracaso (failure function) del patrón como:
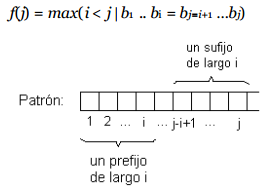
Intuitivamente, f(j) es el largo del mayor prefijo de X que además es sufijo de X. Note que j = 1 es un caso especial, puesto que si hay una discrepancia en b1 el patrón se desliza en una posición.
Si se detecta una discrepancia entre el patrón y el texto cuando se trata de calzar bj+1, se desliza el patrón de manera que bf(j) se encuentre donde bj se encontraba, y se intenta calzar nuevamente.
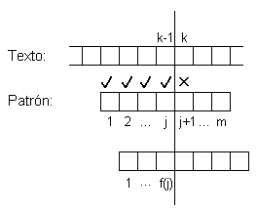
Suponiendo que se tiene f(j) precalculado, la implementación del algoritmo KMP es la siguiente:
// n = largo del texto
// m = largo del patrón
// Los índices comienzan desde 1
int k=0;
int j=0;
while (k<n && j<m)
{
while (j>0 && texto[k]!=patron[j])
{
j=f[j];
}
if (texto[k+1])==patron[j+1]))
{
j++;
}
k++;
}
// j==m => calce, j el patrón no estaba en el texto
Ejemplo:

El tiempo de ejecución de este algoritmo no es difícil de analizar, pero es necesario ser cuidadoso al hacerlo. Dado que se tienen dos ciclos anidados, se puede acotar el tiempo de ejecución por el número de veces que se ejecuta el ciclo externo (menor o igual a n) por el número de veces que se ejecuta el ciclo interno (menor o igual a m), por lo que la cota es igual a O(mn), ¡que es igual a lo que demora el algoritmo de fuerza bruta!.
El análisis descrito es pesimista. Note que el número total de veces que el ciclo interior es ejecutado es menor o igual al número de veces que se puede decrementar j, dado que f(j)<j. Pero j comienza desde cero y es siempre mayor o igual que cero, por lo que dicho número es menor o igual al número de veces que j es incrementado, el cual es menor que n. Por lo tanto, el tiempo total de ejecución es O(n). Por otra parte, k nunca es decrementado, lo que implica que el algoritmo nunca se devuelve en el texto.
Queda por resolver el problema de definir la función de fracaso, f(j). Esto se puede realizar inductivamente. Para empezar, f(1)=0 por definición. Para calcular f(j+1) suponga que ya se tienen almacenados los valores de f(1), f(2), …, f(j). Se desea encontrar un i+1 tal que el (i+1)-ésimo carácter del patrón sea igual al (j+1)-ésimo carácter del patrón.
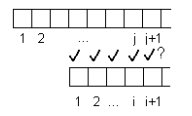
Para esto se debe cumplir que i=f(j). Si bi+1=bj+1, entonces f(j+1)=i+1 . En caso contrario, se reemplaza i por f(i) y se verifica nuevamente la condición.
El algoritmo resultante es el siguiente (note que es similar al algoritmo KMP):
// m es largo del patrón
// los índices comienzan desde 1
int[] f=new int[m];
f[1]=0;
int j=1;
int i;
while (j<m)
{
i=f[j];
while (i>0 && patron[i+1]!=patron[j+1])
{
i=f[i];
}
if (patron[i+1]==patron[j+1])
{
f[j+1]=i+1;
}
else
{
f[j+1]=0;
}
j++;
}
El tiempo de ejecución para calcular la función de fracaso puede ser acotado por los incrementos y decrementos de la variable i, que es O(m).
Por lo tanto, el tiempo total de ejecución del algoritmo, incluyendo el preprocesamiento del patrón, es O(n+m).
Algoritmo de Boyer-Moore
Hasta el momento, los algoritmos de búsqueda en texto siempre comparan el patrón con el texto de izquierda a derecha. Sin embargo, suponga que la comparación ahora se realiza de derecha a izquierda: si hay una discrepancia en el último carácter del patrón y el carácter del texto no aparece en todo el patrón, entonces éste se puede deslizar m posiciones sin realizar niguna comparación extra. En particular, no fue necesario comparar los primeros m-1 caracteres del texto, lo cual
indica que podría realizarse una búsqueda en el texto con menos de n comparaciones; sin embargo, si el carácter discrepante del texto se encuentra dentro del patrón, éste podría desplazarse en un número menor de espacios.
El método descrito es la base del algoritmo Boyer-Moore, del cual se estudiarán dos variantes: Horspool y Sunday.
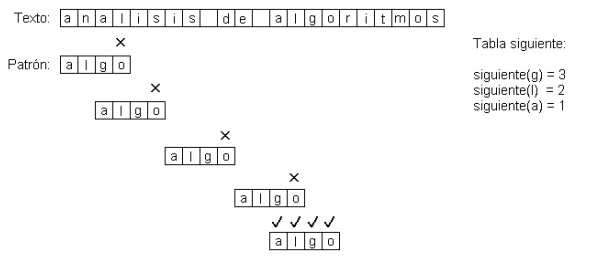
Boyer-Moore-Horspool (BMH)
El algoritmo BMH compara el patrón con el texto de derecha a izquierda, y se detiene cuando se encuentra una discrepancia con el texto. Cuando esto sucede, se desliza el patrón de manera que la letra del texto que estaba alineada con bm, denominada c, ahora se alinie con algún bj, con j<m, si dicho calce es posible, o con b0, un carácter ficticio a la izquierda de b1, en caso contrario (este es el mejor caso del algoritmo).
Para determinar el desplazamiento del patrón se define la función siguiente como:
- 0 si c no pertenece a los primeros m-1 caracteres del patrón (¿Por qué no se considera el carácter bm?).
- j si c pertenece al patrón, donde j<m corresponde al mayor índice tal que bj==c.
Esta función sólo depende del patrón y se puede precalcular antes de realizar la búsqueda.
El algoritmo de búsqueda es el siguiente:
// m es el largo del patrón
// los índices comienzan desde 1
int k=m;
int j=m;
while (k <=n && j>=1)
{
if (texto[k-(m-j)]==patron[j])
{
j--;
}
else
{
k=k+(m-siguiente(a[k]));
j=m;
}
}
// j==0 => calce!, j>=0 => no hubo calce.
Ejemplo de uso del algoritmo BMH:
Se puede demostrar que el tiempo promedio que toma el algoritmo BMH es:
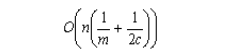
donde c es el tamaño del alfabeto (c<<n). Para un alfabeto razonablemente grande, el algoritmo es O(n/m). En el peor caso, BMH tiene el mismo tiempo de ejecución que el algoritmo de fuerza bruta.
Boyer-Moore-Sunday (BMS)
El algoritmo BMH desliza el patrón basado en el símbolo del texto que corresponde a la posición del último carácter del patrón. Este siempre se desliza al menos una posición si se encuentra una discrepancia con el texto.
Es fácil ver que si se utiliza el carácter una posición más adelante en el texto como entrada de la función siguiente el algoritmo también funciona, pero en este caso es necesario considerar el patrón completo al momento de calcular los valores de la función siguiente. Esta variante del algoritmo es conocida como Boyer-Moore-Sunday (BMS).
¿Es posible generalizar el argumento, es decir, se pueden utilizar caracteres más adelante en el texto como entrada de la función siguiente? La respuesta es no, dado que en ese caso puede ocurrir que se salte un calce en el texto.
